
Note The Moab portions of this tutorial are deprecated, but are included here for historical reference. Moab commands on LC systems are currently provided by wrapper scripts.
Table of Contents
- Abstract
- What is a Workload Manager?
- Workload Managers at LC
- Basic Concepts
- Basic Functions
- Building a Job Script
- Submitting Jobs
- Monitoring Jobs
- Job States and Status Codes
- Exercise 1
- Holding/Releasing Jobs
- Canceling Jobs
- Changing Job Parameters
- Setting Up Dependent Jobs
- Banks and Usage Information
- Output Files
- Guesstimating When Your Job Will Start
- Determining When Your Job's Time is About to Expire
- Running in Standby Mode
- Displaying Configuration and Accounting Information
- Parallel Jobs and the srun Command
- Running Multiple Jobs From a Single Job Script
- Running on Serial Clusters
- Batch Commands Summary
- Exercise 2
- References and More Information
Abstract
Slurm and Moab are two workload manager systems that have been used to schedule and manage user jobs run on Livermore Computing (LC) clusters. Currently, LC runs Slurm natively on most clusters, and provides Moab "wrappers" now that Moab has been decommissioned. This tutorial presents the essentials for using Slurm and Moab wrappers on LC platforms. It begins with an overview of workload managers, followed by a discussion on some basic concepts for workload managers, such as the definition of a job, queues and queue limits, banks and fair-share job scheduling. Basic workload manager functions are covered next, including how to build batch scripts, submit, monitor, change, hold/release, and cancel jobs. Dependent jobs, bank usage information, output files, determining when a job will expire, and running in standby round out the basic workload manager functions. Other topics covered include displaying configuration and accounting information, a discussion on parallel jobs and the srun command, and running on serial clusters. This tutorial includes both C and Fortran example codes and lab exercises.
Level/Prerequisites: The material covered in EC3501: Livermore Computing Resources and Environment would be helpful.
What is a Workload Manager?
- The typical LC cluster is a finite resource that is shared by many users.
- In the process of getting work done, users compete for a cluster's nodes, cores, memory, network, etc.
- In order to fairly and efficiently utilize a cluster, a special software system is employed to manage how work is accomplished.
- Commonly called a Workload Manager. May also be referred to (sometimes loosely) as:
- Batch system
- Batch scheduler
- Workload scheduler
- Job scheduler
- Resource manager (usually considered a component of a Workload Manager)
- Tasks commonly performed by a Workload Manager:
- Provide a means for users to specify and submit work as "jobs"
- Evaluate, prioritize, schedule and run jobs
- Provide a means for users to monitor, modify and interact with jobs
- Manage, allocate and provide access to available machine resources
- Manage pending work in job queues
- Monitor and troubleshoot jobs and machine resources
- Provide accounting and reporting facilities for jobs and machine resources
- Efficiently balance work over machine resources; minimize wasted resources
-
Generalized architecture and workflow of a Workload Manager:

User Workload Manager Cluster - Logs into cluster
- Creates job script and submits it to workload manager
- Monitors and interacts with job via workload manager
- Queries workload manager for job and cluster information
- Typically runs on a separate server as multiple processes
- Receives job submissions, commands, queries from user
- Matches job requirements to available machine resources
- Evaluates, prioritizes and queues jobs
- Schedules jobs for execution on cluster
- Tracks job and cluster information
- Sends jobs to compute node daemons for actual execution
- Workload Manager daemons run on compute nodes
- Daemons manage compute resources and job execution
- Daemons communicate with Workload Manager server processes
-
Some popular Workload Managers include:
- Slurm from SchedMD
- Spectrum LSF from IBM
- Tivoli Workload Scheduler (LoadLeveler) from IBM
- PBS from Altair Engineering
- TORQUE, Maui, Moab from Adaptive Computing
- Univa Grid Engine
- OpenLava
- For a brief overview on batch system concepts, see LC's "Batch System Primer" located at: https://hpc.llnl.gov/banks-jobs/running-jobs/batch-system-primer.

Workload Managers at LC
Slurm
- Slurm is an open-source cluster management and job scheduling system for Linux clusters.
- Slurm is LC's primary Workload Manager. It runs on all of LC's clusters except for the CORAL 2 systems, whose primary workload manager is Flux.
- Used on many of the world's TOP500 supercomputers.
- SchedMD is the primary source for Slurm downloads and documentation. SchedMD also offers development and support services for Slurm.
- Some history:
- Slurm began development as a collaborative effort primarily by Lawrence Livermore National Laboratory (LLNL), Linux NetworX, Hewlett-Packard and Groupe Bull as a free software resource manager in 2001.
- In 2010 LLNL employees Morris (Moe) Jette and Danny Auble incorporated SchedMD LLC, to develop and market Slurm.
- Acronym originally stood for Simple Linux Utility for Resource Management. Not used any longer.
- The Slurm acronym also alludes to the drink Slurm featured in "Fry and the Slurm Factory" from the Futurama TV series: http://en.wikipedia.org/wiki/Fry_and_the_Slurm_Factory
- Documentation:
- SchedMD website: schedmd.com - see the Documentation section.
- LC Running Jobs webpages: hpc.llnl.gov/banks-jobs/running-jobs - see the links for Slurm related docs.
Flux
Flux provides complex resource management through hierarchical, multi-level management and scheduling schemes. It is the scheduler for the CORAL 2 systems like El Capitan and its sibling systems. This tutorial covers Slurm, not Flux, so see https://hpc-tutorials.llnl.gov/flux/ for information about how to use Flux.
Moab (deprecated, 2017)
- Moab is a Workload Manager product from Adaptive Computing, Inc. (www.adaptivecomputing.com).
- Moab was selected via a Tri-lab committee to be the common workload manager for LANL, LLNL and Sandia in August, 2006.
- Moab was decommissioned at all three labs in 2017.
- LC will continue to make most Moab commands available on clusters that run Slurm, via wrapper scripts.
- Documentation:
- LC Running Jobs webpages: hpc.llnl.gov/banks-jobs/running-jobs - see the links for Moab related docs.
Basic Concepts
Jobs
Simple Definition
- To a user, a job can be simply described as a request for compute resources needed to perform computational work.
- Jobs typically specify what resources are needed, such as type of machine, number of machines, job duration, amount of memory required, account to charge, etc.
- Jobs are submitted to the Workload Manager by means of a job script. Job scripts are discussed in the Building a Job Script section of this tutorial.
Slightly More Complex Definition
- A job contains the following components:
- Consumable resources
- Resource and job constraints
- Execution environment
- Credentials
- Consumable resources: Any object which can be utilized ( i.e., consumed and thus made unavailable to another job) by, or dedicated to a job is considered to be a resource. Common examples of resources are a node's physical memory, CPUs or local disk. Network adapters, if dedicated, may also be considered a consumable resource.
- Resource and job constraints: A set of conditions which must be fulfilled in order for the job to start. For example:
- Type of node/machine
- Number of processors
- Speed of processor
- Partition
- Features, such as disk, memory, adapter, etc.
- When the job may run
- Starting job relative to a particular event (i.e., start after job X successfully completes)
- Execution environment: A description of the environment in which the executable is launched. This environment may include attributes such as the following:
- An executable
- Command line args
- Input file
- Output file
- Local user id
- Local group id
- Process resource limits
-
Credentials: With workload managers, credential based policies and limits are often established. At submit time, jobs are associated with a number of credentials which subject the job to various polices and grant it various types of access. For example, querying a job shows that it possesses the following credentials:
Creds: user:jsmith group:jsmith account:cs class:pdebug qos:normal
- user: automatically assigned as your login userid.
- group: automatically assigned as your login group.
- account: automatically assigned as your default bank.
- class (queue): such as "pdebug" or "pbatch"
- qos: "Quality of Service". Provides for assigning special services. The default QoS of "normal" is assigned. Other options include "expedite" and "standby".
Queues and Queue Limits
Queues (also called Pools and/or Partitions):
- The majority of nodes on LC's production systems are designated as compute nodes.
- Compute nodes are typically divided into queues / pools / partitions based upon how they should be used.
- Batch queue:
- Typically comprises most of the compute nodes on a system
- Named pbatch
- Intended for production work
- Configured on all but a few LC systems
- Interactive/debug queue:
- Typically comprises a small number of the compute nodes on a system
- Named pdebug
- Intended for small, short-running interactive and debugging work (not production)
- Configured on most LC systems
- There may be other queues on some machines, such as the viz, pviz, pgpu, etc.
- There are defined limits for each queue, the most important being:
- Max/min number of nodes permitted for a job
- Max wall-clock time - how long a job is permitted to run
- Max number of simultaneous running jobs or max number of nodes permitted across all running jobs.
- No two LC systems have the same queue limits.
- Queue limits can and do change!
- Note
- To run jobs that exceed queue limits, users can request Dedicated Application Time (DAT).
- Login nodes are a shared, limited resource not intended for production work. They are not associated with any queue.
How Do I Find Out What the Queue Limits Are?
-
The easiest way to determine the queue configuration and limits for a particular machine is to login to that machine and use the command:
news job.lim.machinename
- This command is actually just an LC text file displayed with the news utility.
-
Example:
% news job.lim.quartz ================================ job.lim.quartz ================================ SUMMARY OF INTERACTIVE AND BATCH JOB LIMITS ON QUARTZ ------------------------------------------------------------------------ There are 2604 compute nodes, with 36 cores and 128 GiB of memory on each node. Jobs are scheduled per node. Quartz has 2 scheduling pools (or partitions) : pdebug 16 pbatch - 2588 nodes (46872 cores), batch use only. Pools Max nodes/job Max runtime --------------------------------------------------- pdebug 8(*) 30 minutes pbatch 1200 24 hours --------------------------------------------------- (*) Please limit the use of pdebug to 8 nodes on a PER USER basis, not a PER JOB basis, to allow other users access. Using more than the posted limit PER USER can result in job removal without notice. Please be a good neighbor, and be considerate of others utilizing the pdebug partition. Pdebug is scheduled using FIFO (first in, first out). Pdebug is intended for debugging, visualization, and other inherently interactive work. It is NOT intended for production work. Do not use pdebug to run batch jobs. Do not chain jobs to run one after the other. Individuals who misuse the pdebug queue in this or any similar manner will be denied access to running jobs in the pdebug queue. HARDWARE: Each node has 2 18-core Intel Xeon E5-2695 processors (2.1 GHz) and 128 GiB of memory. login: quartz[188,380,386,764,770,962] pbatch: quartz[1-186,193-378,391-762,775-960,967-1338] Quartz uses an Intel Omni-Path Interconnect. Key Documentation in Confluence (on the unclassified side) Using TOSS 3 https://lc.llnl.gov/confluence/display/TCE/Using+TOSS+3 TCE Home https://lc.llnl.gov/confluence/display/TCE/TCE+Home Please call or send email to the LC Hotline if you have questions. LC Hotline phone: 925-422-4531 email: lc-hotline@llnl.gov ================================ job.lim.quartz ================================ - This is the same information available in the LC "Machine Status" web pages: (LC internal). Click on the machine name of interest >
- OCF-CZ: https://lc.llnl.gov/cgi-bin/lccgi/customstatus.cgi
- OCF-RZ: https://rzlc.llnl.gov/cgi-bin/lccgi/customstatus.cgi
- SCF: https://lc.llnl.gov/cgi-bin/lccgi/customstatus.cgi
- It is also available on the "MyLC" web pages. Just click on any machine name in the "machine status" or "my accounts" portlets. Then select the "job limits" tab.
- OCF-CZ: mylc.llnl.gov
- OCF-RZ: rzmylc.llnl.gov
- SCF: https://lc.llnl.gov/lorenz
Banks
Bank Hierarchy
- In order to run on a cluster, you need to have two things:
- Login account: your username appears in /etc/passwd
- LC bank: your username is associated with a valid LC bank
- A bank is part of a hierarchical tree that allocates "shares" of a machine across all users in the cluster.
-
Banks in the hierarchy have parent/child relationships with other banks. For example:
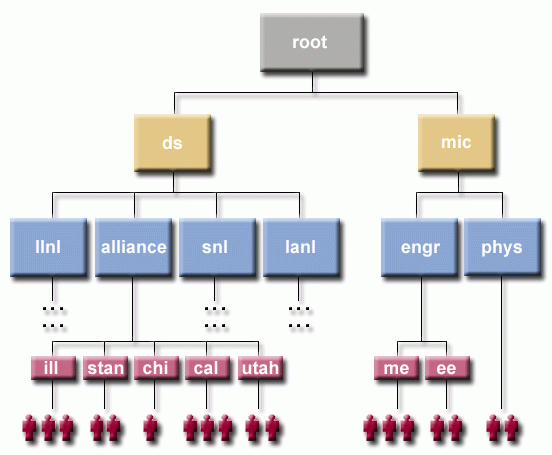
- You may have access to more than one bank.
- The bank hierarchy can differ across clusters, and is also subject to change.
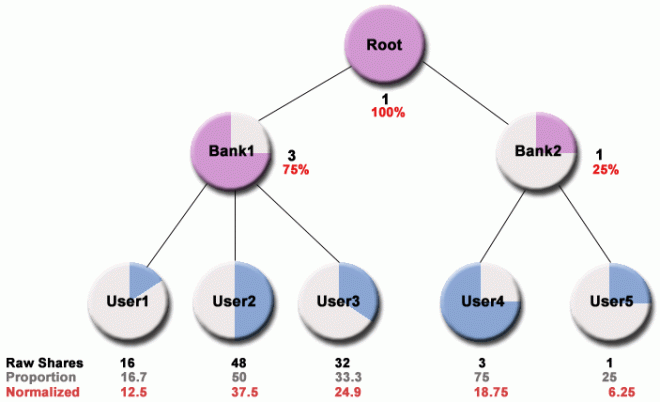
Bank Shares
- Every bank has a specified number of "shares" allocated to it.
- Every user has a share in at least one bank.
-
Your normalized shares represent your percentage of the entire partition.
- The bank hierarchy strongly influences batch job scheduling because shares are assigned and their effects enforced in layers.
- Banks with large allocations can use more cluster resources than banks with smaller allocations
- Banks that use more resources than they are allocated will receive less service.
- Whatever applies to the banks above your bank affects you
- If you have access to multiple banks, you may find one bank gives better service due to the hierarchy and share assignments.

Fair Share Job Scheduling
Why in the World Won't My Job Run?
- Undoubtedly, this is the most commonly asked batch system question.
- Classic scenario: a user submits a job requesting 16 nodes when 50 nodes are shown as available/idle. However, the job sits in the queue and doesn't run. Why?
- Aside from any "user error" related reasons, there are several other, sometimes complicated, reasons.
- Probably the most important reason is the underlying mechanism used by the batch system to determine when/if a job should run.
- At LC, the Workload Manager has been programmed to use a "Fair Share with Half-Life Decay of Usage" algorithm for determining a job's eligibility to run.
Fair Share with Half-Life Decay of Usage:
- This is the primary mechanism used to determine job scheduling. It is based upon a dynamically calculated priority for your job that reflects your share allocation within a bank versus your actual usage.
- Use more than your share, your priority/service degrades
- Use less than your share, your priority/service improves
- Your priority can become very low, but you never "run out of time" at LC.
- Jobs with higher priorities often need to acquire their full set of nodes over time. While their nodes are being reserved, the nodes will appear to be idle.
- Half-Life Decay: Without new usage, your current usage value decays to half its value in two weeks.
- Resources are not wasted:
- Even though your allocation and/or job priority may be small your job will run if machine resources are sitting idle.
- Backfill scheduling - allows waiting jobs to use the reserved job slots of higher priority jobs, as long as they do not delay the start of the higher priority job.
- Scheduling is dynamic with job priorities and usage information being recalculated frequently.
- The details of the Fair Share with Half-Life Decay algorithm are more complex than presented here. See the following document for detailed information: https://slurm.schedmd.com/priority_multifactor.html.
Other Considerations
- Jobs may not start if they request node and/or and time resources which exceed queue limits:
- How long a job may run
- How many nodes a job may use
- Number of jobs that may run simultaneously per user
- Weekday? Weekend? Prime time? Non-prime time?
- Competition with other users: If another user submits a job which calculates to a high priority, your job's position in the waiting (idle) queue can decrease instantly.
- Expedited jobs: System managers (and rarely, privileged users) can make specified jobs "top priority". In effect, the job jumps to the head of the scheduling queue.
- Dedicated Application Time (DAT):
- It is very common for "important" jobs to be scheduled to run in dedicated mode on several LC clusters.
- Other running jobs may be killed, queued jobs put on hold, and new submissions disallowed until the scheduled job completes.
- DAT runs are scheduled in advance and users are notified via the machine-status email lists.
- DATs usually occur on weekends and holidays.
Slurm: Building a Job Script
The Basics
- Users submit jobs to the Workload Manager for scheduling by means of a job script.
- A job script is a plain text file that you create with your favorite editor.
- Job scripts can include any/all of the following:
- Commands, directives and syntax specific to a given batch system
- Shell scripting
- References to environment variables
- Names of executable(s) to run
- Comment lines and white space
-
Simple Slurm and Moab job control scripts appear below:
Slurm Moab (Deprecated) #!/bin/tcsh ##### These lines are for Slurm #SBATCH -N 16 #SBATCH -J parSolve34 #SBATCH -t 2:00:00 #SBATCH -p pbatch #SBATCH --mail-type=ALL #SBATCH -A myAccount #SBATCH -o /p/lustre1/joeuser/par_solve/myjob.out ##### These are shell commands date cd /p/lustre1/joeuser/par_solve ##### Launch parallel job using srun srun -n128 a.out echo 'Done'
#!/bin/tcsh ##### These lines are for Moab #MSUB -l nodes=16 #MSUB -N parSolve34 #MSUB -l walltime=2:00:00 #MSUB -q pbatch #MSUB -m be #MSUB -A myAccount #MSUB -o /p/lustre1/joeuser/par_solve/myjob.out ##### These are shell commands date cd /p/lustre1/joeuser/par_solve ##### Launch parallel job using srun srun -n128 a.out echo 'Done'
Options:
- There are a wide variety of options that can be used in your job script. Some of the more common/useful options are shown below.
-
See the Workload Manager documentation listed in the References section or man pages for details. Or, see the "Batch System Cross-Reference" page.
Slurm Moab (Deprecated) Description/Notes #SBATCH -A account
#MSUB -A account
Defines the account (bank) associated with the job. #SBATCH --begin=time
#MSUB -a time
Declares the time after which the job is eligible for execution. See man page for syntax. #SBATCH -c #
CPUs/cores per task #SBATCH -d list
#MSUB -l depend=list
Specify job dependencies. See "Setting Up Dependent Jobs" for details. #SBATCH -D path
#MSUB -d path
Specifies the directory in which the job should begin executing. #SBATCH -e filename
#MSUB -e filename
Specifies the file name to be used for stderr. #SBATCH --export=list
#MSUB -v list
Specifically adds a list (comma separated) of environment variables that are exported to the job. #SBATCH --license=filesystem
The default is to require no Lustre file systems#MSUB -l gres=filesystem #MSUB -l gres=ignore
The default is to require all mounted Lustre file systems. Use "ignore" to require no file systems (job can run even if file systems are down).
Job requires the specified parallel Lustre file system(s). Valid labels are the names of mounted Lustre parallel file systems, such as lustre1, lustre2. The purpose of this option is to prevent jobs from being scheduled if the specified file systems are unavailable. #SBATCH -H
#MSUB -h
Put a user hold on the job at submission time. #SBATCH -i filename
Specifies the file name to be used for stdin. #SBATCH -J name
#MSUB -N name
Gives a user specified name to the job. default
#MSUB -j oe
Combine stdout and stderr into the same output file. This is the default. If you want to give the combined stdout/stderr file a specific name, include the -o flag also. #SBATCH --mail-type=type (begin, end, fail, requeue, all)
#MSUB -m option(s) (a=abort, b=begin, e=end)
Defines when a mail message about the job will be sent to the user. See the man page for details. #SBATCH -N #
#MSUB -l nodes=#
Node count #SBATCH -n # #SBATCH --ntasks-per-node=# #SBATCH --tasks-per-node=#
#MSUB -l procs=# #MSUB -l ttc=#
Task count (Note that `-n` defines the total number of tasks across all nodes whereas `--ntasks-per-node` sets the number of tasks on each node.) #SBATCH --nice=value
#MSUB -p value
Assigns a user priority value to a job. #SBATCH -o filename
#MSUB -o filename
Defines the file name to be used for stdout. #SBATCH -p partition
#MSUB -q queue
Run the job in the specified partition/queue (pdebug, pbatch, etc.). #SBATCH --qos=exempt #SBATCH --qos=expedite #SBATCH --qos=standby
#MSUB -l qos=exempt #MSUB -l qos=expedite #MSUB -l qos=standby
Defines the quality-of-service to be used for the job. #SBATCH --requeue #SBATCH --no-requeue
#MSUB -r y #MSUB -l resfailpolicy=requeue #MSUB -r n #MSUB -l resfailpolicy=cancel
Specifies whether or not to rerun the job is there is a system failure. The default behavior at LC is to NOT automatically rerun a job in such cases. #MSUB -S path
Specifies the shell which interprets the job script. The default is your login shell. #SBATCH --signal=14@120 #SBATCH --signal=SIGHUP@120
#MSUB -l signal=14@120 #MSUB -l signal=SIGHUP@120
Signaling - specifies the pre-termination signal to be sent to a job at the desired time before expiration of the job's wall clock limit. Default time is 60 seconds. #SBATCH -t time
#MSUB -l walltime= time
Specifies the wall clock time limit for the job. See the man page for syntax. #SBATCH --export=ALL
#MSUB -V
Declares that all environment variables in the job submission environment are exported to the batch job.
Usage Notes
- All #SBATCH / #MSUB lines must come before shell script commands.
- Uppercase vs. lowercase:
- Always use uppercase for the #SBATCH and #MSUB tokens. Otherwise, the token will (usually) be ignored with no error message resulting in the default setting.
- The parameters specified by both tokens are case sensitive
- Batch scheduler syntax is parsed upon job submission. Shell scripting is parsed at runtime. Therefore, it is entirely possible to successfully submit a job that has shell script errors that won't fail until the job actually runs.
- Do not submit binary executables directly (without a script) as they will fail.
- The srun command is required to launch parallel jobs. Discussed later in the Parallel Jobs section.
- Include your preferred shell as the first in your batch script. Otherwise, your job will be rejected. For example:
#!/bin/csh #!/bin/tcsh #!/bin/bash
- dos2unix: This handy utility can be used to "fix" broken batch scripts containing invisible characters that cause the scripts to fail for no apparent reason. See the man page for details.
Slurm: Submitting Jobs
Job Submission Commands
- The sbatch and msub commands are used to submit your job script to the Workload Manager. Upon successful submission, the job's ID is returned and it is spooled for execution.
-
These commands accept the same options as the #SBATCH / #MSUB tokens in a batch script.
-
Examples:
Slurm Moab (Deprecated) % sbatch myjobscript Submitted batch job 645133 % sbatch -p pdebug -A physics myjobscript Submitted batch job 645134
% msub myjobscript 226783 % msub -q pdebug -A physics myjobscript 227243
Usage Notes
- Both sbatch and msub are available on LC clusters:
- Use sbatch to submit job scripts with #SBATCH syntax
- Use msub to submit job scripts with #MSUB syntax
- After you submit your job script, changes to the contents of the script file will have no effect on your job because it has already been spooled to system file space.
- Users may submit and queue as many jobs as they like, up to a reasonable configuration defined limit. The actual number of running jobs per user is usually a lower limit, however. These limits can vary between machines.
- The default directory is where you submit your job from. If you need to be in another directory, then you will need to explicitly cd to, or set the working directory with an #SBATCH / #MSUB option.
Environment Variables
- Most of your usual login environment variables are exported to your job's runtime environment.
- There are #SBATCH / #MSUB options that allow you to explicitly specify environment variables to export, in case they are not exported by default.
- Slurm provides a number of environment variables that allow you to specify/query #SBATCH options and other job behavior. See the sbatch man page for details.
Passing Arguments to Your Job
- Workload Managers do not provide a convenient way to pass arguments to your job.
-
However....sometimes there are "tricks" you can use to accomplish something similar. For example:
This works
% setenv NODES 4 % sbatch -N $NODES myscript % cat myscript #!/bin/tcsh srun -N $NODES hostname
Sample output:quartz244 quartz246 quartz247 quartz245
This doesn't
% setenv NODES 4 % sbatch myscript % cat myscript #!/bin/tcsh #SBATCH -N $NODES srun -N $NODES hostname
Sample output:sbatch: error: "$NODES" is not a valid node count sbatch: error: invalid node count `$NODES'
- Note: Your mileage may vary, depending upon your shell and whether you are using sbatch or msub.
Slurm: Monitoring Jobs
Multiple Choices
- There are several different job monitoring commands. Some are based on Moab, some on Slurm, and some on other sources.
-
The more commonly used job monitoring commands are summarized in the table below, with example output following.
Command Description squeue Displays one line of information per job by default. Numerous options. showq Displays one line of information per job. Similar to squeue. Several options. mdiag -j Displays one line of information per job. Similar to squeue. mjstat Summarizes queue usage and displays one line of information for active jobs. checkjob jobid Provides detailed information about a specific job. scontrol show job jobid Provides detailed information about a specific job. sprio -l
mdiag -p -vDisplays a list of queued jobs, their priority, and the primary factors used to calculate job priority. sview Provides a graphical view of a cluster and all job information. sinfo Displays state information about a cluster's queues and nodes
squeue
- Shows one line of information per job, both running and queued.
- Numerous options for additional/customized output
- Common/useful options:
- -j shows information for a specified job only
- -l shows additional job information
- -o provides customized output - see man page
- -u shows jobs for a specified user only
- squeue man page here
-
Examples below (some output omitted to fit screen):
% squeue JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON) 641412 pbatch job.msub ko33ru2 PD 0:00 160 (Priority) 621487 pbatch psub_34. va556ey2 PD 0:00 12 (Priority) 648530 pbatch psub_26. var556y2 PD 0:00 3 (Dependency) 648627 pbatch restart tiwwar PD 0:00 2 (Dependency) ... 648483 pbatch GEOS.x rryhao R 1:18:04 38 quartz[306-320,1562-1569,2388-2402] 648215 pbatch run_half eerrkawa R 4:28:20 16 quartz[434-437,719,753,778,787,789,834,840... 645278 pbatch DPFMJ link6 R 23:28:01 64 quartz[1088-1107,1976-2001,2127-2144] 648324 pbatch run_half eerrkawa R 2:22:12 32 quartz[516-524,2038-2060] 648636 pbatch rev2 hoewd1 R 9:12 20 quartz[118-130,194-200] 648103 pbatch mxterm thu4r5r3 R 6:32:15 4 quartz[357,881,2061,2089] 648617 pdebug sh labayyn1 R 19:21 2 quartz[14-15]
% squeue -j 683525 JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON) 648634 pbatch ntmp1 tr2erg2 R 8:31 6 quartz[28-33]
% squeue -u eerrkawa JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON) 648215 pbatch run_half eerrkawa R 4:28:20 16 quartz[434-437,719,753,778,787,789,834,840... 648324 pbatch run_half eerrkawa R 2:22:12 32 quartz[516-524,2038-2060]
% squeue -o "%8i %8u %4t %10P %6D %10l %10M %N" JOBID USER ST PARTITION NODES TIMELIMIT TIME NODELIST 647971 pitrrka1 PD pbatch 1000 16:00:00 0:00 647795 ben88on1 PD pbatch 1 1-00:00:00 0:00 624062 dphhhgin R pbatch 48 1-00:00:00 15:33:05 quartz[875-878,1254-1257,1279-1282,1631... 621517 varmmy2 R pbatch 12 14:00:00 13:27:02 quartz[424,488,602,838,1017,1025... ... 621558 varmmy2 R pbatch 3 20:00:00 12:43:08 quartz[2226,2374,2553] 638751 varmmy2 R pbatch 3 12:00:00 50:48 quartz[1846,2264,2435] 648201 dpt6tgin R pbatch 1 4:00:00 50:48 quartz1267 648126 osbiin9 R pbatch 64 3:00:00 40:04 quartz[242,261-262,332,344,354,399,404,408... 648617 labtyan1 R pdebug 2 30:00 23:41 quartz[14-15] 648640 bbergpp2 R pdebug 6 30:00 4:04 quartz[1-6]
showq
- Shows one line of information per job, both running and queued by default.
- Common/useful options:
- -r shows only running jobs
- -i shows only idle jobs
- -b shows only blocked jobs
- -c shows recently completed jobs
- -u shows jobs for a specified user only
- show q man page
-
Examples below (some output omitted to fit screen):
% showq active jobs------------------------ JOBID USERNAME STATE NODES REMAINING STARTTIME 621638 lap345te Running 4 00:11:08 Wed May 10 00:05:57 621640 lap345te Running 4 00:12:25 Wed May 10 00:07:14 648527 ji33a1 Running 6 00:15:11 Wed May 10 15:39:00 ... 648587 abe662 Running 6 00:24:55 Wed May 10 15:48:44 647757 beyyyon1 Running 1 23:58:33 Wed May 10 15:52:22 647758 beyyyon1 Running 1 23:59:51 Wed May 10 15:53:40 113 active jobs 83844 of 93744 processors in use by local jobs (89.44%) eligible jobs------------------------ JOBID USERNAME STATE NODES WCLIMIT QUEUETIME 647971 piuyuka1 Idle 1000 16:00:00 Wed May 10 07:11:53 647770 beuuuon1 Idle 1 1:00:00:00 Wed May 10 05:33:25 648135 bo3pion1 Idle 1 1:00:00:00 Wed May 10 10:12:14 ... 625439 dphi54in Idle 576 1:00:00:00 Fri May 5 11:26:49 622091 kha99r1 Idle 400 1:00:00:00 Thu May 4 16:05:50 648314 trenion1 Idle 1 1:00:00:00 Wed May 10 13:10:31 618 eligible jobs blocked jobs------------------------ JOBID USERNAME STATE NODES WCLIMIT QUEUETIME 359561 pha5516 Idle 12 14:00:00 Fri Mar 31 09:36:08 607661 artqww5 Idle 24 1:00:00:00 Mon May 1 07:29:56 626621 z33g30 Idle 320 1:00:00:00 Fri May 5 21:22:34 ... 641361 to77lusr Idle 16 16:00:00 Mon May 8 16:01:09 648339 quabbie1 Idle 300 16:00:00 Wed May 10 13:39:09 648530 vwerey2 Idle 3 12:00:00 Wed May 10 15:27:56 54 blocked jobs Total jobs: 785
mdiag -j
- Shows one line of information per job, both running and queued.
- Common/useful options:
- -v shows additional job information
- mdiag -j man page here
-
Examples below (some output omitted to fit screen):
% mdiag -j 75025 JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON) 648336 pbatch Ni-0.01- quwwwie1 PD 0:00 300 (Dependency)
% mdiag -j JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON) 641412 pbatch job.msub ko33ru2 PD 0:00 160 (Priority) 621487 pbatch psub_34. va556ey2 PD 0:00 12 (Priority) 648530 pbatch psub_26. var556y2 PD 0:00 3 (Dependency) 648627 pbatch restart tiwwar PD 0:00 2 (Dependency) ... 648483 pbatch GEOS.x rryhao R 1:18:04 38 quartz[306-320,1562-1569,2388-2402] 648215 pbatch run_half eerrkawa R 4:28:20 16 quartz[434-437,719,753,778,787,789,834,840... 645278 pbatch DPFMJ link6 R 23:28:01 64 quartz[1088-1107,1976-2001,2127-2144] 648324 pbatch run_half eerrkawa R 2:22:12 32 quartz[516-524,2038-2060] 648636 pbatch rev2 hoewd1 R 9:12 20 quartz[118-130,194-200] 648103 pbatch mxterm thu4r5r3 R 6:32:15 4 quartz[357,881,2061,2089] 648617 pdebug sh labayyn1 R 19:21 2 quartz[14-15]
mjstat
- Summarizes queue usage and displays one line of information for active jobs.
- Common/useful options:
-
- -r shows only running jobs
- -v shows additional job information
- mjstat man page here
-
Example below (some output omitted to fit screen):
% mjstat ------------------------------------------------------------- Pool Memory CPUs Total Usable Free Other Traits ------------------------------------------------------------- pdebug 1Mb 36 16 16 5 pbatch* 1Mb 36 2588 2584 3 Running job data: --------------------------------------------------------------------------- JobID User Nodes Pool Status Used Master/Other --------------------------------------------------------------------------- 650644 gghod1 30 pbatch PD 0:00 (Resources) 641412 k454ru2 160 pbatch PD 0:00 (Priority) 626626 yggg30 200 pbatch PD 0:00 (Dependency) 650178 biiuion1 1 pbatch PD 0:00 (Priority) 649155 d98uggin 4 pbatch R 12:00:25 quartz111 650459 trerar 2 pbatch R 1:12:38 quartz100 ... 650458 co44rer5 9 pbatch R 1:15:16 quartz1992 650494 c44rier5 9 pbatch R 41:10 quartz714 644450 frjjhel5 25 pbatch R 23:21:25 quartz43 647971 p88urka1 1000 pbatch R 4:21:39 quartz21 625439 yytrggin 576 pbatch R 1:25:47 quartz18 650159 bpeaion9 1 pbatch R 36:14 quartz2312
checkjob
- Displays detailed job state information and diagnostic output for a selected job.
- Detailed information is available for queued, blocked, active, and recently completed jobs.
- The checkjob command is probably the most useful user command for troubleshooting your job, especially if used with the -v and -v -v flags.
- Common/useful options:
- -v shows additional information
- -v -v shows additional information plus job script (if available)
- checkjob man page here
-
Examples below:
% checkjob 650263 job 650263 AName: vasp_NEB_inter_midbot_t2 State: Running Creds: user:vuiuey2 group:vuiuey2 account:ioncond class:pbatch qos:normal WallTime: 01:53:43 of 06:00:00 SubmitTime: Thu May 11 06:50:30 (Time Queued Total: 1:49:46 Eligible: 1:49:46) StartTime: Thu May 11 08:40:16 Total Requested Tasks: 1 Total Requested Nodes: 10 Partition: pbatch Dedicated Resources Per Task: lustre1 Node Access: SINGLEJOB NodeCount: 10 Allocated Nodes: quartz[52,362-363,398-399,444-445,2648-2650] SystemID: quartz SystemJID: 650263 IWD: /p/lustre1/vuiuey2/calculations/radiation/V_Br/NEB_inter_midbot_t2 Executable: /p/lustre1/vuiuey2/calculations/radiation/V_Br/NEB_inter_midbot_t2/psub.vasp User Specified Partition List: quartz System Available Partition List: quartz Partition List: quartz StartPriority: 1000031
% checkjob 648336 (shows a job with diagnostic information) job 648336 AName: Ni-0.01-0.04.f_0.04_res2 State: Idle Creds: user:uuushie1 group:uuushie1 account:nonadiab class:pbatch qos:normal WallTime: 00:00:00 of 16:00:00 SubmitTime: Wed May 10 13:38:30 (Time Queued Total: 21:04:25 Eligible: 00:00:00) StartTime: 0 Total Requested Tasks: 1 Total Requested Nodes: 300 Depend: afterany:648335 Partition: pbatch Dedicated Resources Per Task: lustre1 Node Access: SINGLEJOB NodeCount: 300 SystemID: quartz SystemJID: 648336 IWD: /p/lustre1/uuushie1/bigfiles/alpha_in_nickel/velocities/0.04.ff-redo Executable: /p/lustre1/uuushie1/bigfiles/alpha_in_nickel/velocities/0.04.ff-redo/s_restart2.sh User Specified Partition List: quartz System Available Partition List: quartz Partition List: quartz StartPriority: 1 NOTE: job can not run because it's dependency has not been met. (afterany:648335)
scontrol show job
- Similar to checkjob
- Can not be used with completed jobs
- scontrol man page here
-
Example below:
% scontrol show job 2835312 JobId=2835312 JobName=zGaAs_phonon_final_pressures_1200K_It2 UserId=janedoe(58806) GroupId=janedoe(58806) MCS_label=N/A Priority=1342000 Nice=0 Account=qtc QOS=normal JobState=RUNNING Reason=None Dependency=(null) Requeue=0 Restarts=0 BatchFlag=1 Reboot=0 ExitCode=0:0 RunTime=00:28:37 TimeLimit=01:02:00 TimeMin=N/A SubmitTime=2019-05-22T15:40:56 EligibleTime=2019-05-22T15:40:56 StartTime=2019-05-24T09:30:59 EndTime=2019-05-24T10:32:59 Deadline=N/A PreemptTime=None SuspendTime=None SecsPreSuspend=0 LastSchedEval=2019-05-24T09:30:59 Partition=pbatch AllocNode:Sid=quartz380:1253 ReqNodeList=(null) ExcNodeList=(null) NodeList=quartz[819,909,966,1001,1064,1066] BatchHost=quartz819 NumNodes=6 NumCPUs=216 NumTasks=6 CPUs/Task=1 ReqB:S:C:T=0:0:*:* TRES=cpu=216,node=6,billing=216 Socks/Node=* NtasksPerN:B:S:C=0:0:*:* CoreSpec=* MinCPUsNode=1 MinMemoryNode=0 MinTmpDiskNode=0 Features=(null) DelayBoot=00:00:00 Gres=(null) Reservation=(null) OverSubscribe=NO Contiguous=0 Licenses=(null) Network=(null) Command=/usr/WS1/janedoe/GaAs/phonons/final-pressures/zGaAs/1200K/Iteration2/10.0GPa/13/Submit.SLURM WorkDir=/usr/WS1/janedoe/GaAs/phonons/final-pressures/zGaAs/1200K/Iteration2/10.0GPa/13 StdErr=/usr/WS1/janedoe/GaAs/phonons/final-pressures/zGaAs/1200K/Iteration2/10.0GPa/13/slurm-2835312.out StdIn=/dev/null StdOut=/usr/WS1/janedoe/GaAs/phonons/final-pressures/zGaAs/1200K/Iteration2/10.0GPa/13/slurm-2835312.out Power=
sprio -l & mdiag -p -v
- Displays a list of queued jobs, their priority, and the primary factors used to calculate job priority.
- These commands show identical output.
-
To sort the job list by priority use the command:
sprio -l | sort -r -k 4,4 mdiag -p -v | sort -r -k 4,4
- Useful for determining where your jobs are queued relative to other jobs. Highest priority jobs are at the top of the list.
- Man pages:
-
Example below (some output omitted to fit screen):
% sprio -l JOBID PARTITION USER PRIORITY AGE FAIRSHARE JOBSIZE PARTITION QOS NICE 626621 pbatch yyyg30 1001015 324 692 0 0 1000000 0 669823 pbatch vuuuey2 1000526 524 2 0 0 1000000 0 669836 pbatch vuuuey2 1000496 494 2 0 0 1000000 0 670732 pbatch m998eson 1000903 870 34 0 0 1000000 0 671723 pbatch couoni 1000824 278 547 0 0 1000000 0 671842 pbatch p66716 1000703 703 1 0 0 1000000 0 674730 pbatch p667a1 1002698 201 2497 0 0 1000000 0 ... 675982 pbatch p998v2 1043716 15 43701 0 0 1000000 0 675984 pbatch rl233sey 1145228 14 145214 0 0 1000000 0 675985 pbatch ed444ton 1019905 14 19892 0 0 1000000 0 675988 pbatch rl233sey 1145225 12 145214 0 0 1000000 0 675993 pbatch a000hn 1064602 9 64593 0 0 1000000 0
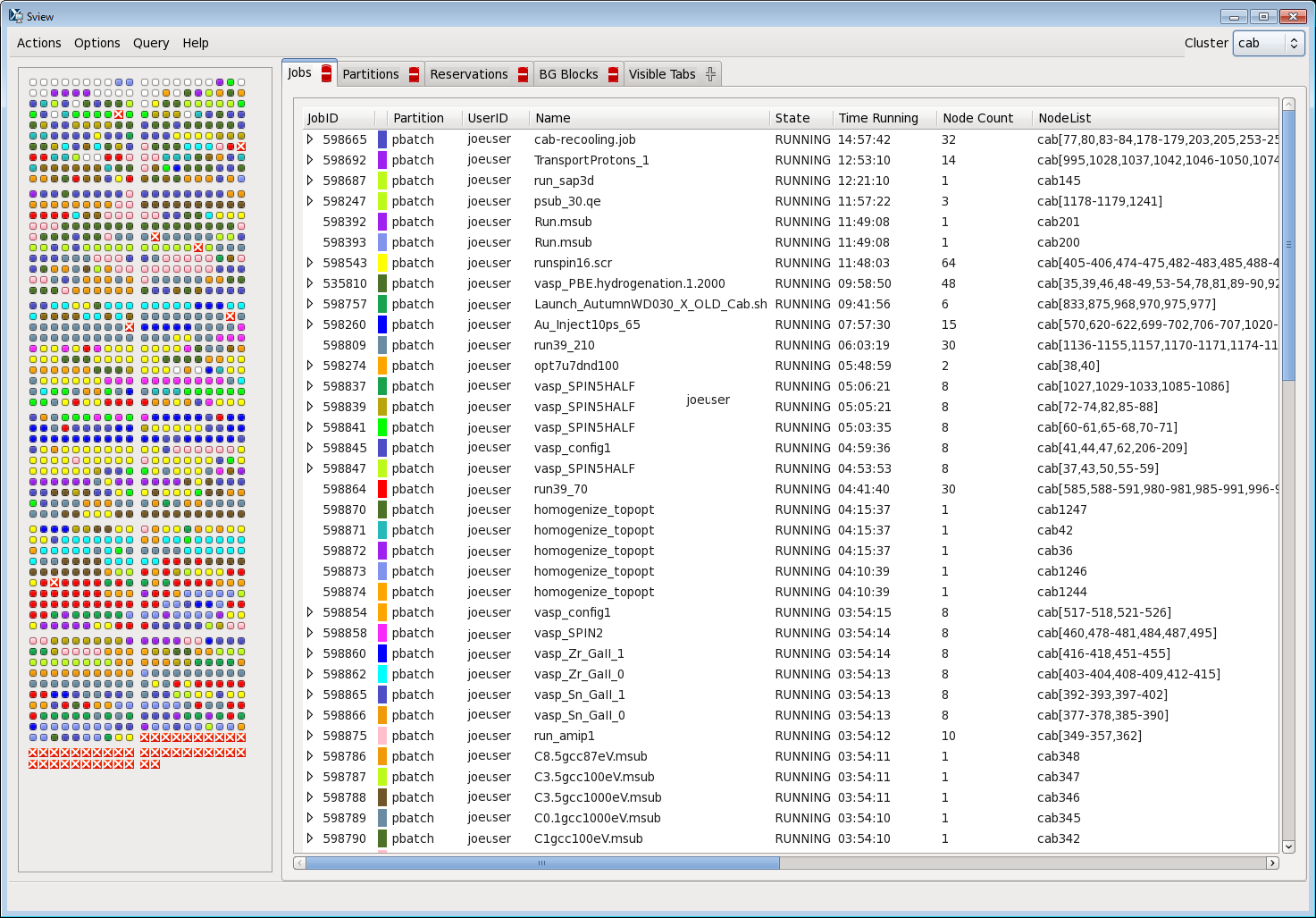
sview
- Graphically displays all user jobs on a cluster, nodes used, and detailed job information for each job.
- sview man page here
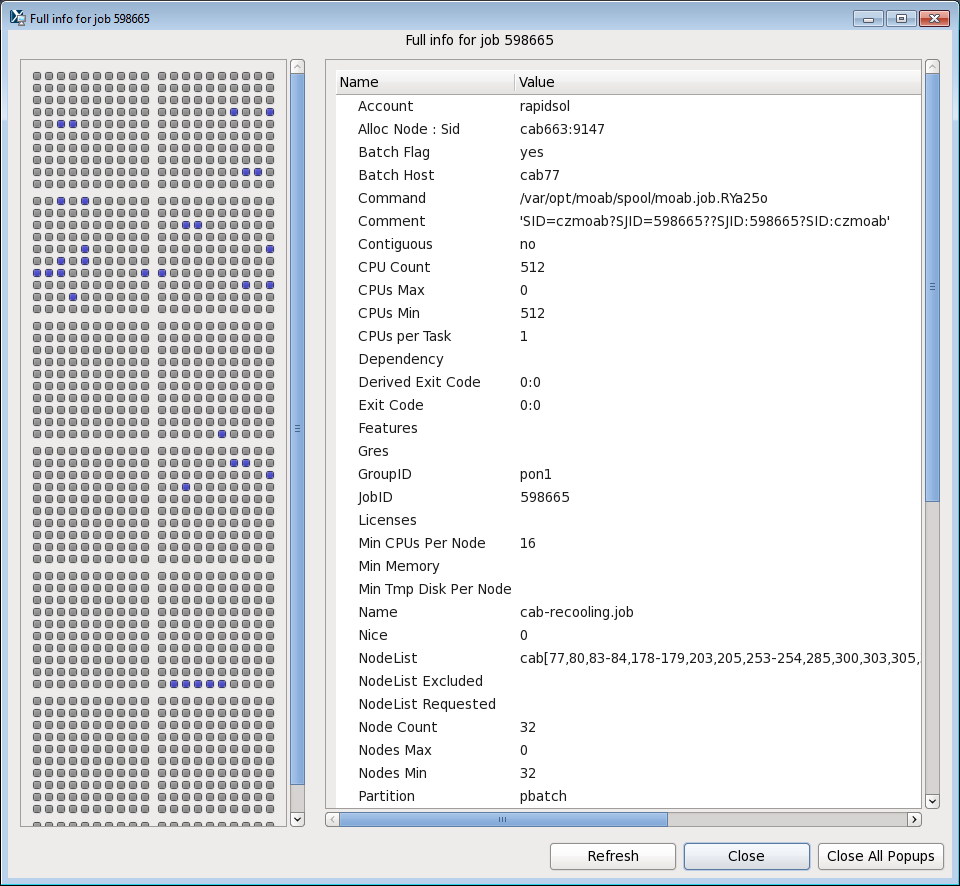
sinfo
- Displays state information about a cluster's queues and nodes
- Numerous options for additional/customized output
- Common/useful options:
- -s summarizes queue information
- sinfo man page here
- Examples below:
% sinfo PARTITION AVAIL TIMELIMIT NODES STATE NODELIST pdebug up 30:00 3 alloc quartz[1-3] pdebug up 30:00 13 idle quartz[4-16] pbatch* up 1-00:00:00 3 drain* quartz[1321,2037,2593] pbatch* up 1-00:00:00 1 drain quartz2183 pbatch* up 1-00:00:00 2584 alloc quartz[17-186,193-378,391-762,775- 1146,1159-1320,1322-1530,1543-1914,1927-2036,2038-2182,2184-2298,2311-2496, 2503-2592,2594-2688] % sinfo -s PARTITION AVAIL TIMELIMIT NODES(A/I/O/T) NODELIST pdebug up 30:00 11/5/0/16 quartz[1-16] pbatch* up 1-00:00:00 2584/0/4/2588 quartz[17-186,193-378,391-762, 775-1146,1159-1530,1543-1914,1927-2298,2311-2496,2503-2688] |
Job States and Status Codes
- Job state and status codes usually appear in the output of job monitoring commands. Most are self-explanatory.
- For details, consult the man page for the relevant command.
-
The table below describes commonly observed job state and status codes.
Job State/Status Description BatchHold
SystemHold
UserHold
JobHeldUserJob is idle and is not eligible to run due to a user, admin, or batch system hold. Canceling
CA CANCELLEDJob is cancelled or in the process of being cancelled. Completed
CD COMPLETED
CG COMPLETINGJob is in the process of, or has completed running. Deferred Job can not be run for one reason or another, however it will continue to evaluate the job periodically for run eligibility. Depend
DependencyJob can not run because it has a dependency. F FAILED Job terminated with non-zero exit code or other failure condition. NF NODE_FAIL Job terminated due to failure of one or more allocated nodes. Idle Job is queued and eligible to run but is not yet executing. Migrated This is a transitional state that indicates that the job is in being handed off to the native Slurm resource manager on a specific machine in preparation for running. NotQueued Indicates a system problem in most cases. PD PENDING Job is awaiting resource allocation. Priority One or more higher priority jobs exist for this partition. Removed Job has run to its requested walltime successfully but has been canceled by the scheduler or resource manager due to exceeding its walltime or violating another policy; includes jobs canceled by users or administrators either before or after a job has started. Resources The job is waiting for resources to become available. Running
R RUNNINGJob is currently executing the user application. Staging The job has been submitted to the batch system for it to run but the batch system has not confirmed yet that the job is actually running. Starting The batch system has attempted to start the job and the job is currently performing pre-start tasks which may including provisioning resources, staging data,executing system pre-launch scripts, etc. Suspended
S SUSPENDEDJob was running but has been suspended by the scheduler or an admin. The user application is still in place on the allocated compute resources but it is not executing. TimeLimit
TO TIMEOUTJob terminated upon reaching its time limit. Vacated Job canceled after partial execution due to a system failure.
Exercise 1
Getting Started
Overview
- Login to an LC cluster using your workshop username and OTP token
- Copy the exercise files to your home directory
- Familiarize yourself with the cluster's batch configuration
- Familiarize yourself with the cluster's bank allocations
- Create a job batch script
- Submit and monitor your batch job
- Check your job's output
Approx. 20 minutes
Slurm: Basic Functions
Holding and Releasing Jobs
Holding Jobs:
-
Users can place their jobs in a "user hold" state several ways:
Where/When Slurm Moab (Deprecated) Job script #SBATCH -H
#MSUB -h
Command line
(when submitted)sbatch -H jobscript
msub -h jobscript
Command line
(queued job)scontrol hold jobid
mjobctl -h jobid
-
Jobs placed in a user hold state will be shown as such in the output of the various job monitoring commands.
-
Running jobs cannot be placed on hold.
-
Note that jobs can be placed on system hold status by the workload manager or by system administrators. Not covered here.
-
Examples (Slurm):
Placing a job on hold at submission time:
% sbatch -H myjob Submitted batch job 650974 % squeue -j 650974 JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON) 650974 pbatch T4.CMD joeuser PD 0:00 2 (JobHeldUser)
Placing a job on hold after it was submitted:
% sbatch myjob Submitted batch job 651001 % squeue -j 651001 JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON) 651001 pbatch T3.CMD joeuser PD 0:00 128 (Priority) % scontrol hold 651001 % squeue -j 651001 JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON) 651001 pbatch T3.CMD joeuser PD 0:00 128 (JobHeldUser)
Releasing Jobs:
-
To release a queued job from a user hold state:
Slurm Moab (Deprecated) scontrol release jobid
mjobctl -u jobid
-
Example (Slurm):
% squeue -j 651001 JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON) 651001 pbatch T3.CMD joeuser PD 0:00 128 (JobHeldUser) % scontrol release 651001 % squeue -j 651001 JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON) 651001 pbatch T3.CMD joeuser PD 0:00 128 (Priority)
Canceling Jobs
-
To cancel either running or queued jobs:
Slurm Moab (Deprecated) scancel jobid canceljob jobid
mjobctl -c jobid
- Both scancel and canceljob can be used to cancel multiple jobs at the same time.
- The scancel command has a number of options to specify criteria for job cancellation. See the scancel man page for details.
-
Examples (Slurm):
% scancel 23692
% scancel -i 651040 Cancel job_id=651040 name=T2.CMD partition=pbatch [y/n]? y
% canceljob 23458 23459 23460 job '23458' cancelled job '23459' cancelled job '23460' cancelled
Changing Job Parameters
- Only a few job parameters can be changed after after a job is submitted. These parameters include:
- job dependency (change to "none")
- queue
- job name
- number of nodes (decrease only)
- user priority
- wall clock limit
- parallel file system dependency
- account
- qos
- For the most part, these parameters can only be changed for queued (non-running) jobs.
- Note there is virtually no documentation for this feature.
-
Examples:
Parameter Slurm Moab (Deprecated) syntax scontrol update job=jobid parameter=value
mjobctl -m parameter=value jobid
dependency (set to "none") scontrol update job=651070 depend=none
mjobctl -m depend=none 651070
queue scontrol update job=651070 partition=pdebug
mjobctl -m queue=pdebug 651070
job name scontrol update job=651070 name=alphaScan
mjobctl -m jobname=alphaScan 651070
nodes (decrease) scontrol update job=651070 numnodes=4
mjobctl -m nodes=4 651070
user priority scontrol update job=651070 prio=100
mjobctl -m userprio=100 651070
wall clock limit scontrol update job=651070 timelimit=2:00:00
mjobctl -m wclimit=2:00:00 651070
parallel file system scontrol update job=651070 gres=ignore
mjobctl -m gres=ignore 651070
account scontrol update job=651070 account=physics
mjobctl -m account=physics 651070
qos scontrol update job=651070 qos=standby
mjobctl -m qos=standby 651070
Setting Up Dependent Jobs
-
If a job depends upon the completion of one or more other jobs, you can specify this several ways:
Where Slurm Moab (Deprecated) Command line sbatch -d 52628 jobscript sbatch -d after:52628:52629:52630 jobscript sbatch -d afterany:52628:52629:52630 jobscript
msub -l depend=33523 jobscript msub -l depend="33523 33524 33525" jobscript
Job script
(for this job)#SBATCH -d 52628 #SBATCH -d after:52628:52629:52630 #SBATCH -d afterany:52628:52629:52630
#MSUB -l depend=33523 #MSUB -l depend="33523 33524 33525"
Job script
(for next job)# $SLURM_JOBID is current job's id # Submit next job dependent on this job sbatch jobscript -d $SLURM_JOBID
# $SLURM_JOBID is current job's id # Submit next job dependent on this job msub jobscript -l depend=$SLURM_JOBID
- See the sbatch man page for additional Slurm dependency options.
-
Checking/verifying job dependency - use the checkjob jobid command.
% checkjob 652974 job 652974 AName: T3.CMD State: Idle Creds: user:joeuser group:joeuser account:lc class:pbatch qos:normal WallTime: 00:00:00 of 01:40:00 SubmitTime: Fri May 12 10:03:57 (Time Queued Total: 00:00:10 Eligible: 00:00:00) StartTime: 0 Total Requested Tasks: 1 Total Requested Nodes: 2 Depend: afterjob:652628:652973:652971 Partition: pbatch Dedicated Resources Per Task: ignore Node Access: SINGLEJOB NodeCount: 2 SystemID: quartz SystemJID: 652974 IWD: /g/g0/joeuser/moab Executable: /g/g0/joeuser/moab/t3.cmd User Specified Partition List: quartz System Available Partition List: quartz Partition List: quartz StartPriority: 1 NOTE: job can not run because it's dependency has not been met. (after:652628:652973:652971)
Banks and Usage Information
Overview
- As discussed previously, in order to run on a cluster, you need to have two things:
- Login account: your username appears in /etc/passwd
- Bank: your username is associated with a valid bank
- Banks are hierarchical and determine the percentage of machine resources (cycles) you are entitled to receive, as discussed in the Banks section of this tutorial.
-
Every cluster has its own unique bank structure. To view the entire bank hierarchy, use the command:
mshare -t root
- You may have an allocation in more than one bank.
- If you belong to more than one bank, your banks are not necessarily shared across all of the clusters where you have a login account.
- You have a default bank on each cluster, which may/may not be the same on other clusters.
mshare
- Displays bank structure, allocations and usage information
- If you want to see your available banks and usage stats for a cluster, this is the best command to use.
- This is also the best command for viewing your place within the entire bank hierarchy.
- mshare man page here
-
Examples below:
% mshare Partition cab USERNAME ACCOUNT --------SHARES-------- ---USAGE--- ALLOCATED NORMALIZED NORMALIZED joeuser bdivp 1.0 0.03318% 0.00000% joeuser ices 1.0 0.56895% 1.39241% joeuser tmi 1.0 0.26551% 0.00000% joeuser cms 1.0 0.32245% 1.03216%
% mshare -t root (lots of output deleted) Partition cab U/A NAME A/P NAME --------SHARES-------- ---USAGE--- ALLOCATED NORMALIZED NORMALIZED root root 1.0 100.00000% 100.00000% root root 1.0 0.98039% 0.00000% ds root 60.0 58.82353% 61.09482% uqpline ds 17.0 10.00000% 0.00000% alliance ds 30.0 17.64706% 17.90455% caltech alliance 14.0 2.47059% 0.00000% user1 caltech 1.0 0.30882% 0.00000% user2 caltech 1.0 0.30882% 0.00000% user3 utah 1.0 0.08824% 0.00000% dnt ds 47.0 27.64706% 42.28668% a dnt 30.0 8.29412% 0.56933% adev a 5.0 4.14706% 0.31294% user1 adev 1.0 0.17279% 0.00000% axcode adivp 75.0 1.23180% 0.06002% user1 aprod 1.0 0.35546% 0.00000% user2 aprod 1.0 0.35546% 0.00000% b dnt 30.0 8.29412% 21.11694% bdev b 5.0 4.14706% 0.00000% user1 bdev 1.0 0.29622% 0.00000% lc overhead user1 lc 1.0 0.00302% 0.00000% user2 lc 1.0 0.00302% 0.00000% user3 lc 1.0 0.00302% 0.00000% none overhead 1.0 0.00980% 0.00000% sa overhead 74.0 0.72549% 0.00000% da sa 1.0 0.14510% 0.00000% user1 sa 1.0 0.14510% 0.00000% user2 sa 1.0 0.14510% 0.00000%
mdiag -u
- Shows which banks and qos are available.
- If you do not specify a username, it will display all users.
-
Example below (some output deleted to fit screen):
% mdiag -u joeuser User Def Acct Cluster Account Share ... QOS ---------- ---------- ---------- ---------- --------- ------------------ joeuser quartz peml2 1 normal,standby joeuser quartz cbronze 1 normal,standby joeuser quartz pemwork 1 normal,standby joeuser quartz libqmd 1 normal,standby joeuser quartz dbllayer 1 normal,standby
sreport
- Reports usage information for a cluster, bank, individual, date range, and more.
- sreport man page here
-
Example: show usage by user (in hours) for the alliance bank on the cluster cab between the dates shown.
% sreport -t hours cluster AccountUtilizationByUser accounts=alliance cluster=cab start=2/1/12 end=3/1/12 -------------------------------------------------------------------------------- Cluster/Account/User Utilization 2012-02-01T00:00:00 - 2012-02-29T23:59:59 (2505600 secs) Time reported in CPU Hours -------------------------------------------------------------------------------- Cluster Account Login Proper Name Used --------- --------------- --------- --------------- ---------- cab alliance 2739237 cab caltech 500080 cab caltech br4e33t Joe User 500076 cab caltech sthhhd6 Bill User 4 cab michigan 844339 cab michigan dhat67s Mary User 261 cab michigan hetyyr2 Sam User 38552 ... ...
Output Files
Defaults
- The batch output file is named slurm-jobid.out
- stdout and stderr are combined into the same batch output file.
- Will be written to the directory where you issued the sbatch or msub command.
- The name of a job has no effect on the name of the output file.
- If an output file with the same name already exists, new output will append to it.
Assigning Unique Output File Names
- Use the -o and -e options to uniquely name your output files - either on the command line or within your job script.
- Use %j to include the jobid, and %N to include the node name in the output file.
-
Examples:
Slurm Moab (Deprecated) #SBATCH -o /g/g11/joeuser/myjob.out #SBATCH -o myjob.out.%j #SBATCH -o myjob.out.%N #SBATCH -o myjob.out.%j.%N
#MSUB -o /g/g11/joeuser/myjob.out #MSUB -o myjob.out.%j #MSUB -o myjob.out.%N #MSUB -o myjob.out.%j.%N
sbatch -e /g/g11/joeuser/myjob.err jobscript sbatch -o $HOME/proj12/myjob.out jobscript sbatch -o myjob.out.%j jobscript
msub -e /g/g11/joeuser/myjob.err jobscript msub -o $HOME/proj12/myjob.out jobscript msub -o myjob.out.%j jobscript
Caveats:
-
#SBATCH / #MSUB tokens in a job script do not interpret the ~ (tilde) character or $VARIABLE in file names. These will be interpreted however, by the command line sbatch and msub commands.
- Erroneous file paths are not checked or reported upon.
Guesstimating When Your Job Will Start
- One of the most frequently asked questions is "When will my job start?".
- Because job scheduling is dynamic, and can change at any moment, picking an exact time is often impossible.
- There are a couple ways that you can get an estimate on when your job will start, based on the current situation.
- The easiest way is to use the checkjob command. Look for the StartTime line - if it exists. Note that not all jobs will show a start time.
-
For example:
% checkjob 830063 job 830063 AName: OSU_IMPI51_ICC_64_run_2 State: Idle Creds: user:e889till group:e889till account:asccasc class:pbatch qos:normal WallTime: 00:00:00 of 01:00:00 SubmitTime: Wed Jun 14 09:12:48 (Time Queued Total: 5:06:19 Eligible: 5:06:19) StartTime: Thu Jun 15 00:02:00 Total Requested Tasks: 1 Total Requested Nodes: 64 Partition: pbatch Dedicated Resources Per Task: ignore Node Access: SINGLEJOB NodeCount: 64 SystemID: quartz SystemJID: 830063 IWD: /g/g91/e889till/batcher Executable: /g/g91/e889till/batcher/quartz.job User Specified Partition List: quartz System Available Partition List: quartz Partition List: quartz StartPriority: 1000147 NOTE: job can not run because there are higher priority jobs.
-
Sometimes the squeue --start command can be used to get an estimate for job start times (and sometimes it can't). For example:
% squeue --start JOBID PARTITION NAME USER ST START_TIME NODES NODELIST(REASON) 2173337 pbatch job.txt is456i1 PD 2017-06-28T15:31:58 1 (Priority) 2173338 pbatch job.txt is456i1 PD 2017-06-28T15:36:02 1 (Priority) 2173339 pbatch job.txt is456i1 PD 2017-06-28T16:25:37 1 (Priority) 2173340 pbatch job.txt is456i1 PD 2017-06-28T16:26:37 1 (Priority) 2173341 pbatch job.txt is456i1 PD 2017-06-28T16:35:37 1 (Priority) ... 2174947 pbatch S180_10p bbbmons3 PD 2017-07-03T19:28:33 1 (Priority) 1247698 pdebug ppmd_IA6 vvvang PD N/A 2 (PartitionNodeLimit) 1863133 pbatch runme tttite PD N/A 4 (PartitionNodeLimit) 2156487 pbatch surge110 mrtrang1 PD N/A 1 (Dependency) 2163499 pbatch voh mrtrang1 PD N/A 1 (Dependency)
-
You can also view the position of your job in the queue relative to other jobs. Either of the commands below will give you a list of idle jobs sorted by priority - highest priority is at the top of the list.
sprio -l | sort -r -k 4,4 mdiag -p -v | sort -r -k 4,4
-
For example (some output deleted to fit screen):
% sprio -l | sort -r -k 4,4 JOBID PARTITION USER PRIORITY AGE FAIRSHARE JOBSIZE PARTITION QOS NICE 830811 pbatch aaarg2 1321517 0 321517 0 0 1000000 0 830760 pbatch saaa4 1189400 6 189394 0 0 1000000 0 830759 pbatch saaa4 1189400 6 189394 0 0 1000000 0 830776 pbatch saaa4 1189397 3 189394 0 0 1000000 0 830775 pbatch ddwa9 1189397 3 189394 0 0 1000000 0 830774 pbatch rrra8 1189397 3 189394 0 0 1000000 0 ... 830366 pbatch zhhhh49 1000127 127 0 0 0 1000000 0 830365 pbatch taffhh2 1000127 128 0 0 0 1000000 0 830369 pbatch zhhhh49 1000125 125 0 0 0 1000000 0 830493 pbatch wwwg102 1000102 86 16 0 0 1000000 0 830576 pbatch jjjtega 1000090 31 60 0 0 1000000 0 830810 pbatch e988till 1000000 0 0 0 0 1000000 0 829743 pbatch yyymel2 1000000 0 0 0 0 1000000 0
Determining When Your Job's Time is About to Expire
- Determining when your job's time is about to expire is useful for cleaning up, writing checkpoint files or other data, and exiting gracefully.
- One common way to accomplish this is to request the batch system to send your job a signal shortly before its time expires.
- Another common way is to query/poll the batch system to determine how much time remains.
Signaling Method
- You can send a specific signal your job at a designated time before the job is scheduled to terminate.
-
Syntax:
signal=signal@seconds_remaining
-
Examples:
Where/When Slurm Moab (Deprecated) Job script #SBATCH --signal=1@120 #SBATCH --signal=SIGHUP@120
#MSUB -l signal=1@120 #MSUB -l signal=SIGHUP@120
Command line
(when submitted)sbatch --signal=1@120 jobscript sbatch --signal=SIGHUP@120 jobscript
msub -l signal=1@120 jobscript msub -l signal=SIGHUP@120 jobscript
Command line
(queued job)scancel --signal=1 24897 scancel --signal=SIGHUP 24897
mjobctl -N signal=1 24897 mjobctl -N signal=SIGHUP 24897
- In order to use this method, you will need to write a signal handler as part of your code.
- You'll also need to know the valid signal numbers/names on the system you're using. These are usually included in a system header file, such as /usr/include/bits/signum.h on LC Linux systems.
-
Simple example:
#include <stdio.h> #include <signal.h> void do_cleanup(){ printf("doing cleanup activities...\n"); } void user_handler(int sig){ do_cleanup(); printf("in user_handler, got signal=%d\n",sig); exit(1); } int main (int argc, char *argv[]) { signal(SIGHUP, user_handler); sleep(12000); }
Polling Method
- From within a running job, you can determine when its time will expire. This is accomplished by calling a routine from within your source code.
- yogrt_remaining()
- A locally developed library. Stands for "Your Only Get Remaining Time" routine. yogrt_remaining man page available
- slurm_get_rem_time()
- Returns the number of seconds remaining before the expected termination time of a specified Slurm job id. slurm_get_rem_time man page available
More on yogrt_remaining
- Need to include yogrt.h
- Need to link with -lyogrt. This may/may not be in your default LIBPATH. Currently, libyogrt is located in /usr/lib64 on LC machines. If you can't find it, try using the command: findentry yogrt_remaining.
-
Simple example:
#include <yogrt.h> main (int argc, char **argv) { long t; int i; for (i=0; i<10; i++) { t = yogrt_remaining(); printf("Remaining time= %li\n",t); sleep(5); } }
Running in Standby Mode
- Jobs can have a Quality of Service (QOS) of:
- normal - usual case; default
- exempt - overrides normal policies, limits; requires LC authorization
- expedite - highest priority; requires LC authorization
- standby - lowest priority
- At LC, "standby" designates a quality of service (QOS) credential that permits jobs to be preempted/terminated if their resources are needed by non-standby jobs.
- Typically employed by users who wish to take advantage of available cycles on a machine, but need to yield to other users with higher priority work. For example:
- User A has low (or no) priority on a cluster, but wishes to take advantage of free cycles.
- User B has higher priority for work on the cluster
- User A submits jobs to the cluster with a QOS of standby
- User A jobs will run to completion if User B doesn't submit jobs with a non-standby (normal) QOS
- If User B submits jobs that need the nodes being used by User A jobs, then User A jobs will be automatically terminated, and User B jobs will acquire the needed nodes.
- Job terminations are immediate and without a warning/signal being sent.
-
Running in standby QOS can be set upon job submission or after the job is queued, but before it actually begins to run:
Where/When Slurm Moab (Deprecated) Job script #SBATCH --qos=standby
#MSUB -l qos=standby
Command line
(when submitted)sbatch --qos=standby
msub -l qos=standby
Command line
(queued job)scontrol update job=jobid qos=standby
mjobctl -m qos=standby jobid
Displaying Configuration and Accounting Information
What's Available?
- Several commands can be used to display system configuration and user accounting information.
- Most of this information is for system managers, though it can prove useful to users as well.
- Note that some commands may not be available for all users and/or may be reserved for system managers.
- The table below summarizes some of the more common/useful commands.
-
See the relevant man pages for details:
Command Description mdiag -a
Lists accounts mdiag -c
Queue information mdiag -f
Fair-share scheduler information mdiag -j mdiag -j -v
Job information mdiag -n
Node information mdiag -q
Quality of service information mdiag -p mdiag -p -v sprio
Priority information mdiag -r
Reservation information mdiag -u
User information sacct sacct -a
Lists current jobs and their associated accounts scontrol show job scontrol show job jobid
Detailed job information scontrol show node scontrol show node nodename
Detailed node configuration information scontrol show partition scontrol show partition partitionname
Detailed queue configuration information scontrol show config
Detailed Slurm configuration information scontrol show version
Display Slurm version sshare -l
Displays shares, usage and fairshare information
Parallel Jobs and the srun Command
srun Command
- The Slurm srun command is required to launch parallel jobs - both batch and interactive.
- It should also be used to launch serial jobs in the pdebug and other interactive queues.
-
Syntax:
srun [option list] [executable] [args]
Note that srun options must precede your executable.
-
Interactive use example, from the login node command line. Specifies 2 nodes (-N), 72 tasks (-n) and the interactive pdebug partition (-p):
% srun -N2 -n72 -ppdebug myexe
-
Batch use example requesting 16 nodes and 576 tasks (assumes nodes have 36 cores):
Slurm Moab (Deprecated) First create a job script that requests nodes and uses srun to specify the number of tasks and launch the job: #!/bin/tcsh #SBATCH -N 16 #SBATCH -t 2:00:00 #SBATCH -p pbatch # Run info and srun job launch cd /p/lustre1/joeuser/par_solve srun -n576 a.out echo 'Done'
#!/bin/tcsh #MSUB -l nodes=16 #MSUB -l walltime=2:00:00 #MSUB -q pbatch # Run info and srun job launch cd /p/lustre1/joeuser/par_solve srun -n576 a.out echo 'Done'
Then submit the job script from the login node command line: % sbatch myjobscript
% msub myjobscript
-
Primary differences between batch and interactive usage:
Difference Interactive Batch Where used: From login node command line In batch script Partition: Requires specification of an interactive partition, such as pdebug with the -p flag pbatch is default Scheduling: If there are available interactive nodes, job will run immediately. Otherwise, it will queue up (fifo) and wait until there are enough free nodes to run it. The batch scheduler handles when to run your job regardless of the number of nodes available. -
More Examples:
srun -n64 -ppdebug my_app
64 process job run interactively in pdebug partition srun -N64 -n512 my_threaded_app
512 process job using 64 nodes. Assumes pbatch partition. srun -N4 -n16 -c4 my_threaded_app
4 node, 16 process job with 4 cores (threads) per process. Assumes pbatch partition. srun -N8 my_app
8 node job with a default value of one task per node (8 tasks). Assumes pbatch partition. srun -n128 -o my_app.out my_app
128 process job that redirects stdout to file my_app.out. Assumes pbatch partition. srun -n32 -ppdebug -i my.inp my_app
32 process interactive job; each process accepts input from a file called my.inp instead of stdin
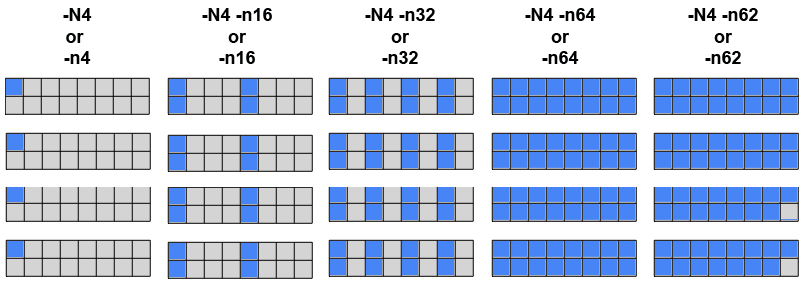
Task Distribution and Binding for Batch Jobs:
- The LC default is for the scheduler to distribute tasks as evenly as possible across the allocated nodes.
-
Examples: if 4 nodes (with 16 cores each) are requested by a batch job using:
#SBATCH -N 4 #MSUB -l nodes=4
then the behavior of srun -N and -n flags will be as follows:
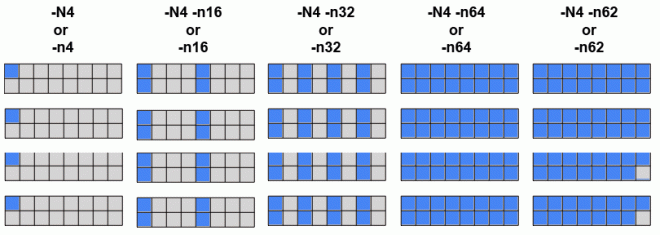
- Additionally, tasks are bound to specific cores to promote better cache utilization.
- Threads associated with a task are likewise bound to the same cores.
srun Options
- srun is a powerful command with @100 options affecting a wide range of job parameters.
- For example:
- Accounting
- Number and placement of processes/threads
- Process/thread binding
- Job resource requirements; dependencies
- Mail notification options
- Input, output options
- Time limits
- Checkpoint, restart options
- and much more....
- Some srun options may be set via @60 Slurm environment variables. For example, SLURM_NNODES behaves like the -N option.
- See the srun man page for details.
Parallel Output
- Please use a parallel file system for parallel I/O. Lustre parallel file systems are mounted under /p/lustre#.
- It's a good idea to launch parallel jobs from a parallel file system even if they aren't doing much I/O. A core dump on a parallel job can hang a non-parallel file system easily. Core dumps are written to the directory where you launched your job.
- It is not uncommon for an entire file system to "hang" because a user inadvertently directs output from a large parallel job to an NFS mounted file system.
- NFS file systems include your home directory and /usr/workspace directories.
Running Multiple Jobs From a Single Job Script
Motivation:
- It is certainly possible to run more than one job from a single job script. In fact it is common.
- The primary motivation is avoid having each individual job sit in the wait queue.
- Combining multiple jobs into a single job script means there is only one wait in the queue for the entire job group.
Sequential:
- If one job is dependent upon the completion of a previous job, then this method can be used.
- When you submit your job script, be sure to specify enough wall clock time to cover all of the included jobs.
- Individual jobs can vary in the number of nodes used, provided none of them exceed the number of nodes allocated to your encompassing job script.
-
Example below. Assumes 36 cores per node: 16 nodes * 36 cores = 576 tasks max.
Slurm Moab (Deprecated) #!/bin/tcsh #SBATCH -N 16 #SBATCH -t 12:00:00 srun -n576 myjob1 srun -n576 myjob2 srun -N16 -n288 myjob3 srun -N12 -n432 myjob4
#!/bin/tcsh #MSUB -l nodes=16 #MSUB -l walltime=12:00:00 srun -n576 myjob1 srun -n576 myjob2 srun -N16 -n288 myjob3 srun -N12 -n432 myjob4
Simultaneous
- This method can be used if there are no dependencies between jobs.
- When you submit your job script, be sure to specify enough nodes to cover all of the included jobs.
- You can vary the number of nodes used by individual jobs as long as the aggregate number of nodes doesn't exceed the number of nodes allocated to your encompassing job script.
- Important to remember:
- Put each individual job "in the background" using an ampersand - otherwise they will run sequentially.
- Include a wait statement to ensure the job script doesn't terminate prematurely.
- With your srun commands, be sure to explicitly specify how many nodes each job requires - or else the scheduler will think each job has access to all nodes, with possible complications.
-
Example 1: every job uses the same number of nodes/tasks.
Assumes 36 cores per node: 16 nodes * 36 cores = 576 tasks max.Slurm Moab (Deprecated) #!/bin/tcsh #SBATCH -N 16 #SBATCH -t 12:00:00 srun -N4 -n144 myjob1 & srun -N4 -n144 myjob2 & srun -N4 -n144 myjob3 & srun -N4 -n144 myjob4 & wait
#!/bin/tcsh #MSUB -l nodes=16 #MSUB -l walltime=12:00:00 srun -N4 -n144 myjob1 & srun -N4 -n144 myjob2 & srun -N4 -n144 myjob3 & srun -N4 -n144 myjob4 & wait
-
Example 2: jobs differ in the number of nodes/tasks used.
Assumes 36 cores per node: 16 nodes * 36 cores = 576 tasks max.Slurm Moab (Deprecated) #!/bin/tcsh #SBATCH -N 16 #SBATCH -t 12:00:00 srun -N4 -n144 myjob1 & srun -N2 -n72 myjob2 & srun -N8 -n8 myjob3 & srun -N2 -n16 myjob4 & wait
#!/bin/tcsh #MSUB -l nodes=16 #MSUB -l walltime=12:00:00 srun -N4 -n144 myjob1 & srun -N2 -n72 myjob2 & srun -N8 -n8 myjob3 & srun -N2 -n16 myjob4 & wait
Running on Serial Clusters

Different than Other Clusters
- Some of LC's clusters do not have an interconnect; they are designated as serial/single-node parallelism resources:
- borax: OCF-CZ, 36 cores/node
- rztrona - OCF-RZ, 36 cores/node
- agate - SCF, 36 cores/node
- Because of this, LC schedules jobs on these nodes very differently than the parallel clusters with interconnects:
- Jobs are scheduled according to the number of processes/cores required - NOT the number of nodes.
- All jobs, including parallel jobs are limited to one node - there is no internode communication.
- If your job doesn't use all of the cores on a node, other jobs may be scheduled to run on the same node.
- The default allocation for job scheduling is one core per job.
-
Since multiple user jobs can be scheduled on the same node, it is critical that users tell the scheduler how many cores their job actually requires.
Example of 8 different jobs by 4 different users running on a single 8-core node. Notice that these jobs are each using 100% CPU:

- Bad things can happen if you (or someone else) uses more than this without telling the scheduler:
- More tasks than cores means jobs run longer than expected and can run out of time and be terminated prematurely
- Memory can be exhausted and jobs die and/or the node crashes
- Some examples of how this can happen:
- A job that creates threads, either through OpenMP or Pthreads. Each thread uses a core. The default of 1 core will be inadequate.
- A job that calls an application (that it doesn't own) that creates new MPI processes. Each process uses a core. The default of 1 core will be inadequate.
How to Specify the Right Number of Cores:
-
Simply include the appropriate Slurm / Moab option:
Slurm Moab (Deprecated) Notes -n #cores
-l ttc=#cores
Syntax: where #cores specifies the total number of cores for your job, including all spawned threads and MPI processes. #SBATCH -n 4
#MSUB -l ttc=4
In job script sbatch -n 4 jobscript
msub -l ttc=4 jobscript
From command line - Matching srun with your Slurm / Moab option - see the table below for examples of correct and incorrect settings. Note that the #SBATCH / #MSUB jobscript syntax is shown, but the same would also apply to the command line.
-
Note: Hyperthreading is turned on and will actually allow you to run 2X processes for the number of cores requested.
Slurm Moab (Deprecated) Comments #SBATCH -n 8 srun -n8 a.out
#MSUB -l ttc=8 srun -n8 a.out
Correct. Uses 8 processes on 8 cores. #SBATCH -n 4 srun -n16 a.out
#MSUB -l ttc=4 srun -n16 a.out
Incorrect. Uses more processes than 2X the requested cores. #SBATCH -n 4 srun -n16 -O a.out
#MSUB -l ttc=4 srun -n16 -O a.out
This will work because the -O option permits Slurm to oversubscribe (more than 2X) the requested number of cores. However, using more tasks than cores is not recommended and can degrade performance. srun -n4 a.out
srun -n4 a.out
Incorrect. The #SBATCH / #MSUB option isn't specified so the default of 1 core is less than required by the -n4 tasks specified with srun. #SBATCH -n 8 srun -n2 a.out
#MSUB -l ttc=8 srun -n2 a.out
This will work and might be used if each of 2 tasks spawns 4 threads. However, if the 2 tasks don't actually use all 8 cores, this would be wasteful. #SBATCH -n 48 srun -n48 a.out
#MSUB -l ttc=48 srun -n48 a.out
Incorrect. The #SBATCH / #MSUB option specifies more cores than are physically available (36) on agate, borax and rztrona nodes. -
You can use the mjstat command to verify the number of cores being used for a job. Example below (some output deleted to fit screen):
% % mjstat Scheduling pool data: ------------------------------------------------------------- Pool Memory Cpus Total Usable Free Other Traits ------------------------------------------------------------- pdebug 1Mb 36 3 3 3 pbatch* 1Mb 36 40 39 0 Running job data: --------------------------------------------------------------------------- JobID User Procs Pool Status Used Master/Other --------------------------------------------------------------------------- 1886921 aaanion1 36 pbatch PD 0:00 (Resources) 1886966 aaanion1 36 pbatch PD 0:00 (Priority) 1887122 aaanion1 36 pbatch PD 0:00 (Priority) ... 1886841 aaanion1 36 pbatch R 36:24 borax12 1887113 cahhhh 2 pbatch R 1:03:36 borax27 1887114 cahhhh 2 pbatch R 1:03:36 borax27 1887115 cahhhh 2 pbatch R 1:03:36 borax27 1887738 ooodsky3 2 pbatch R 1:00:36 borax28 1887739 ooodsky3 2 pbatch R 1:00:36 borax28 1247698 lyaeee 64 pdebug PD 0:00 (PartitionNodeLimit) 1880597 lyaeee 32 pdebug PD 0:00 (PartitionTimeLimit)
Batch Commands Summary
- For convenience, the table below summarizes a number of useful batch system commands discussed in this tutorial.
- Most commands have multiple options (not shown here).
-
Hyperlinked commands will take you to additional information. Most commands have man pages.
Command Description canceljob Cancel a running or queued job checkjob Display detailed information about a single job mdiag -f Display usage and fair-share scheduler statistics mdiag -j Display running, idle and blocked jobs mdiag -p Display a list of queued jobs, their priority, and the primary factors used to calculate job priority mdiag -u Display a user's bank/account information mjobctl -c Cancel a running or queued job mjobctl -h Place a queued job on user hold mjobctl -m Change a job's parameters mjobctl -N -signal Signal a running job mjobctl -u Release a user held job mjstat Display queue summary and running jobs mshare Display bank/account allocations, usage statistics, and priorities msub Submit a job script to the batch system. Many options. news job.lim.machinename Display job limits and machine information sacct -j Display information about a running job, including multiple job steps sbatch Submit a job script to the batch system. Many options. scancel Cancel a running or queued job scancel --signal Signal a running job scontrol hold Place a queued job on user hold scontrol release Release a user held job scontrol show job Display detailed job information scontrol show partition Display detailed queue information scontrol update Change a job's parameters showq Display running, idle and blocked jobs sinfo Display a concise summary of queues and running jobs sprio Display a list of queued jobs, their priority, and the primary factors used to calculate job priority squeue Display running jobs sreport Report usage information for a cluster, bank, individual, date range, and more srun Launch a parallel job from within a job script or interactively sshare Display bank/account allocations, usage statistics, and fair-share information sview Graphically display a map of jobs, nodes they are running on, and additional detailed job information
Exercise 2
More Basic Functions
Overview:
- Login to an LC workshop cluster, if you are not already logged in
- Holding and releasing jobs
- Canceling jobs
- Running in standby mode
- Running parallel and hybrid parallel jobs
- Running multiple jobs from a single batch script
- When will a job start?
- Try sview
References and More Information
- Original Author: Blaise Barney; Contact: hpc-tutorials@llnl.gov, Livermore Computing.
- LC's Slurm, Moab and LSF web pages: https://hpc.llnl.gov/banks-jobs/running-jobs
Links currently include:- Batch System Primer
- LSF User Manual
- LSF Quick Start Guide
- LSF Commands
- Slurm User Manual
- Slurm Quick Start Guide
- Slurm Commands
- Moab User Manual
- Batch System Cross-Reference
- Slurm information from SchedMD:
http://www.schedmd.com/ - Moab information from Adaptive Computing
http://www.adaptivecomputing.com/
Note: No longer relevant at LC because all Moab commands are wrapper scripts and Moab was decommissioned in 2017.