
This page describes how El Capitan uses the Spindle tool to accelerate library loading during program startup. It gives background on what Spindle does, discusses tuning and configuration of Spindle, and provides examples.

Background
When programs first launch, they need to locate and load shared libraries from the shared file system such as NFS. This can be an expensive operation, as they search every directory in their search paths for every library they expect to load. When performed at scale, tens- to hundreds- of thousands of processes try to do library loads at once and overwhelm the shared file system. This can lead to application startup times measured in hours, and other users experience horrible file system performance.
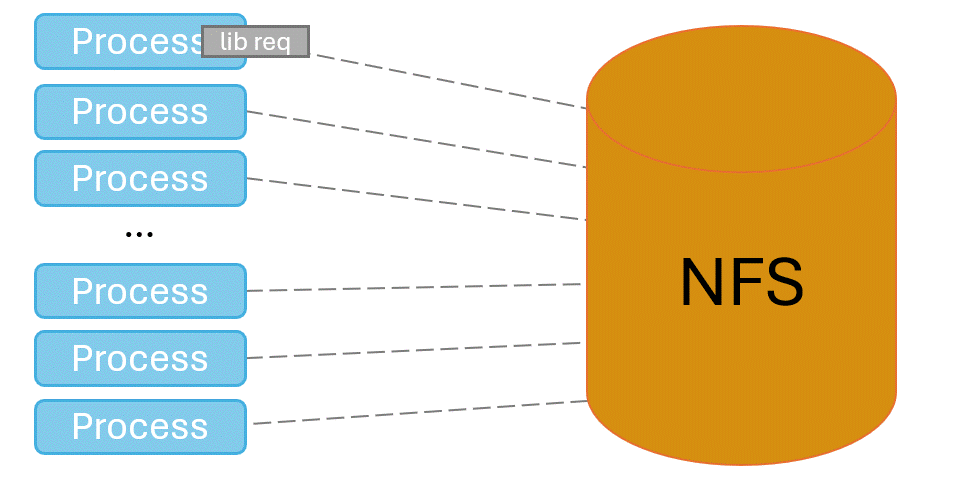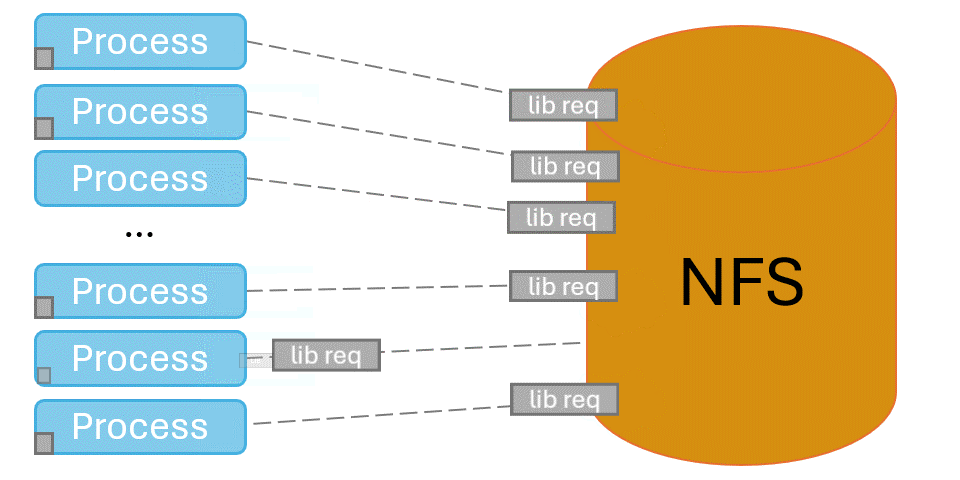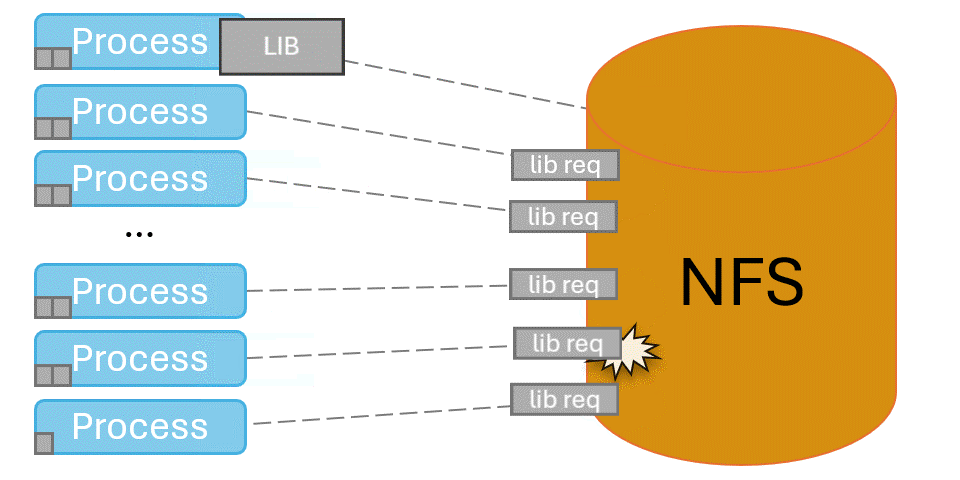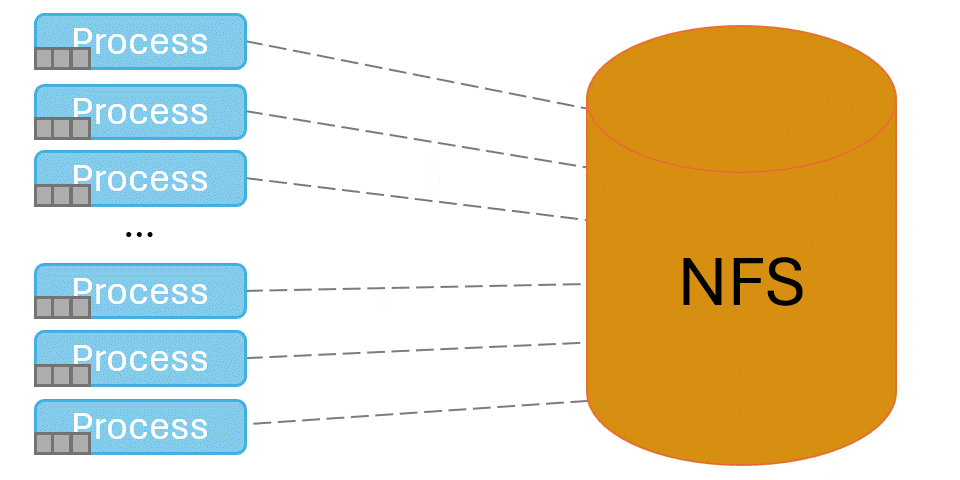
Spindle solves this problem by injecting itself into the application’s library loading routines and coordinating library loads. One designated process loads libraries from the shared file system, then broadcasts their contents to the rest of the job via the system’s network.
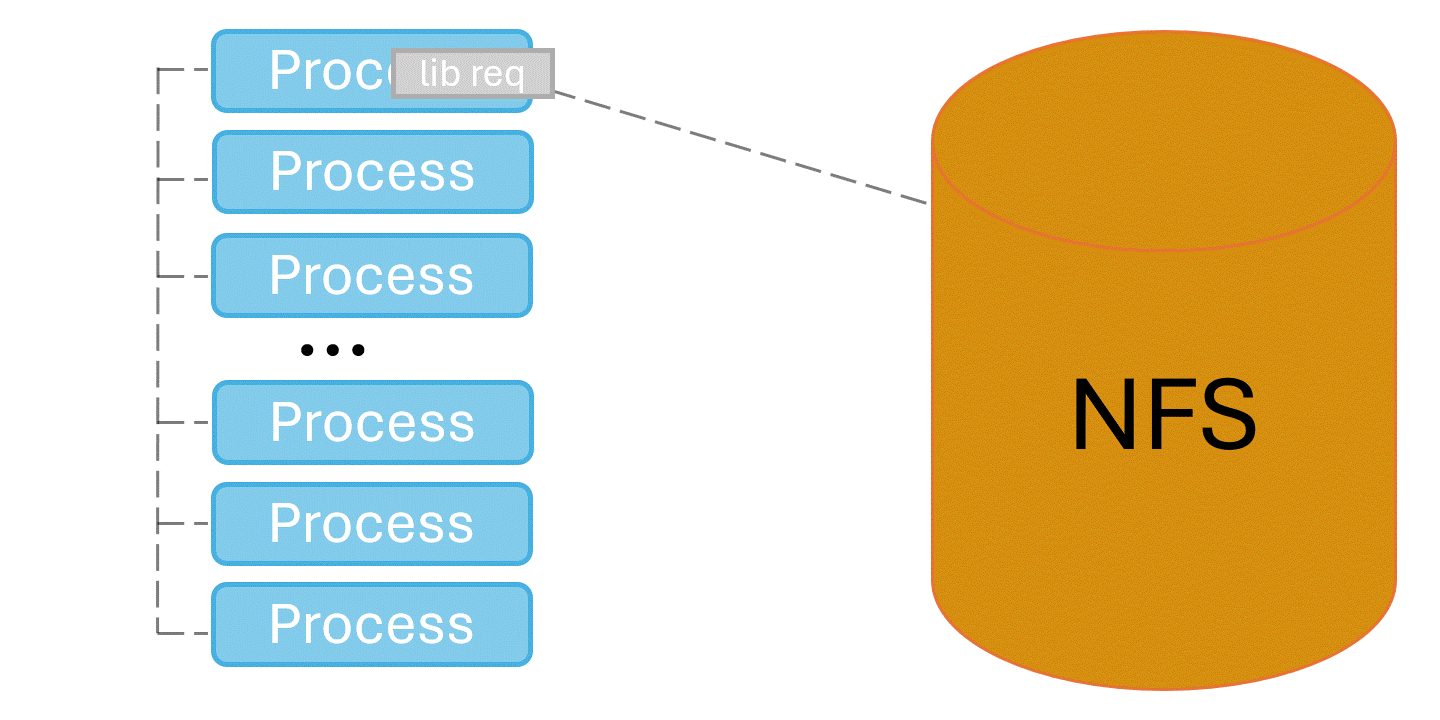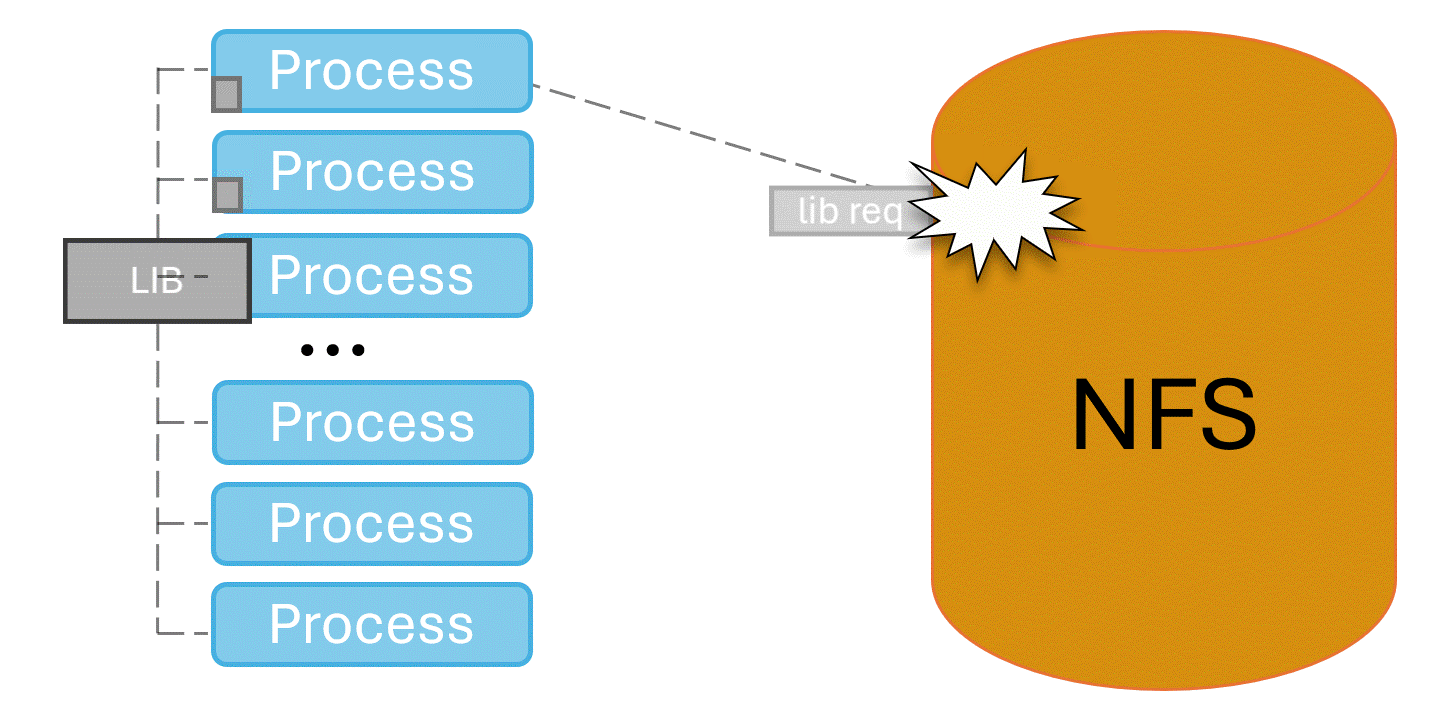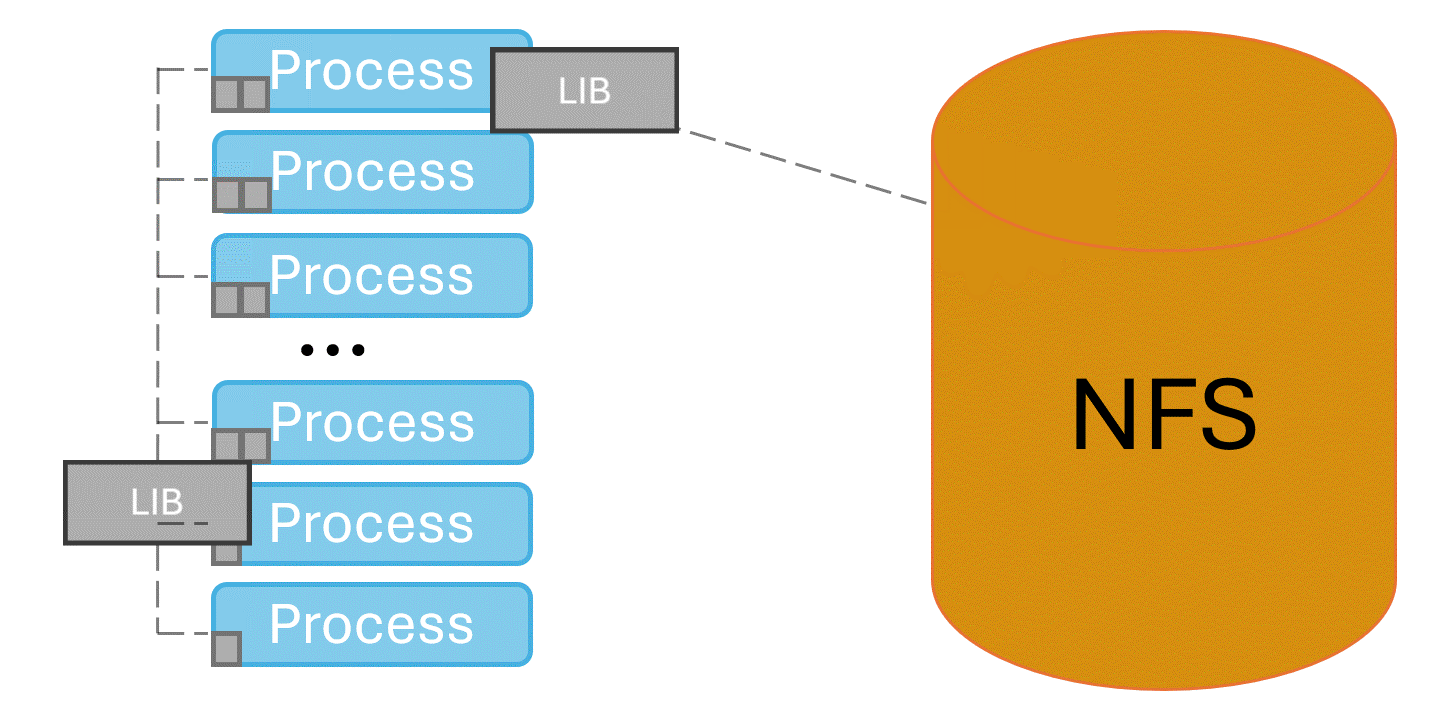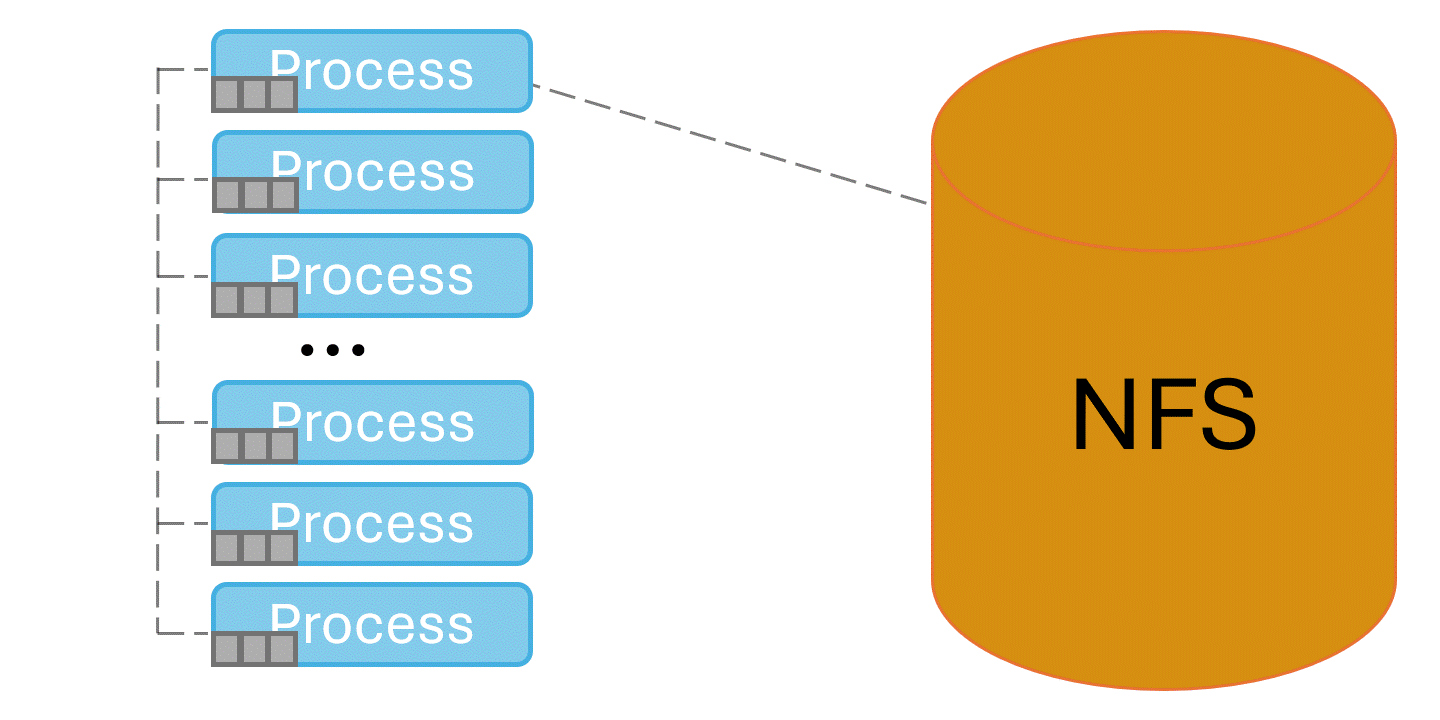
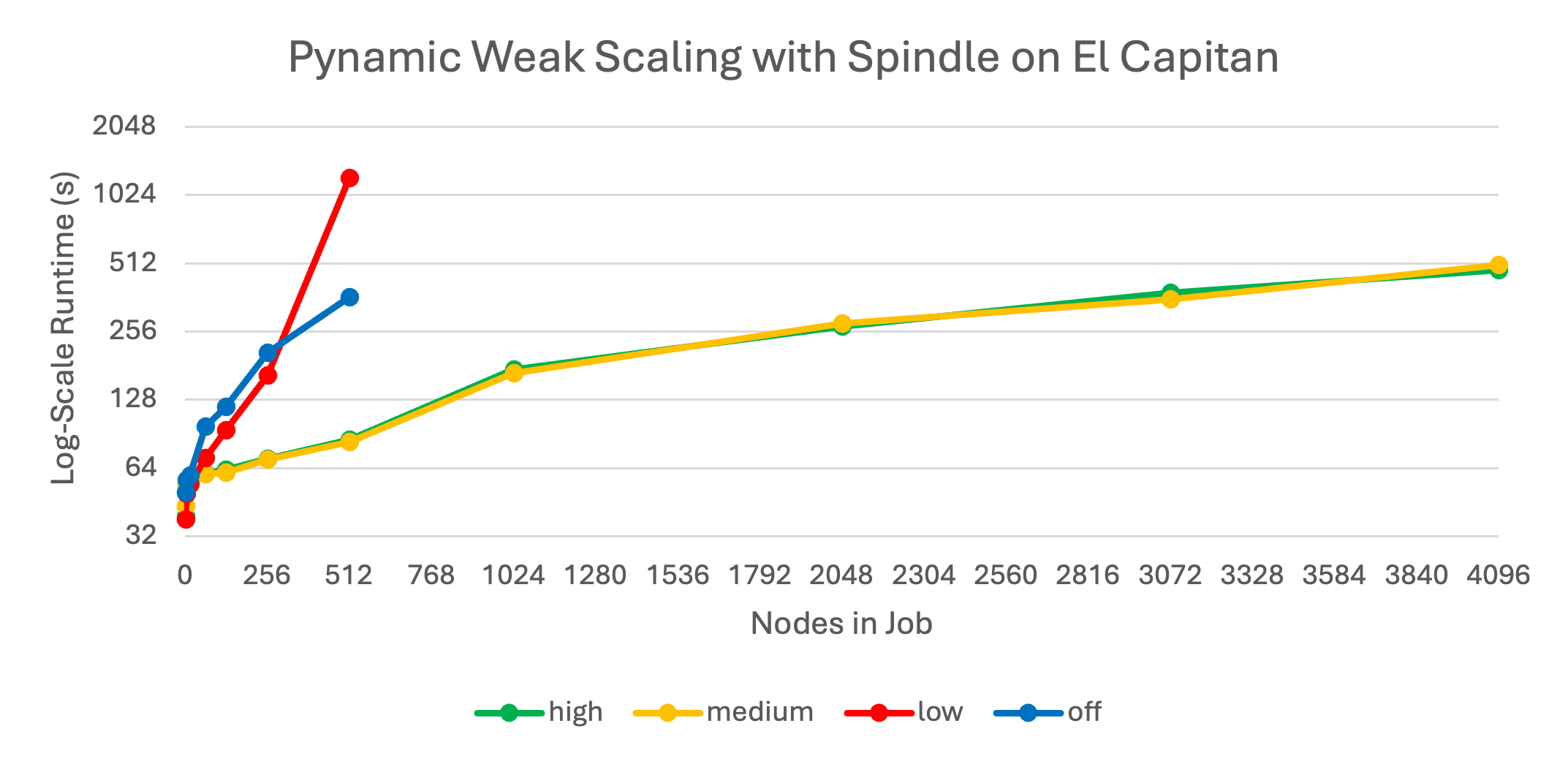
Under spindle applications can launch at scale without taking hours and overwhelming the shared file system. Figure 3 shows a benchmark running under spindle at scale on El Capitan. When spindle’s caching mechanism is set to low or off (see the Tuning Spindle’s Caching Level section below) the application scales poorly and hammers the file system as it starts. At spindle levels medium and high the application starts up scalably, and is not hammering the file system as it runs.
In addition to libraries, Spindle can also scalably load Python files, executables, and user-configurable data files.
Using Spindle
On El Capitan and Tuolumne, Spindle is automatically turned on for every job. You do not need to take extra steps to run spindle. It’s tuned to run traditional simulation jobs reasonably.
Tuning Spindle
When launching spindle through flux run you can set options by putting -o spindle.OPTION or -o spindle.OPTION=VALUE on the flux run command line.
When using spindle sessions (see below), options are passed on the spindle command line. Running spindle --help shows the available options.
Disabling Spindle
To turn spindle off, set the environment variable SPINDLE_FLUXOPT to ‘off’. Please discuss with system administrators before turning spindle off and then running at scale.
Tuning for Many Jobs
Spindle is currently tuned to accelerate loading of a single job. If running many jobs, (e.g., with flux submit/bulksubmit, or just lots of flux runs), you can use the spindle sessions feature to have spindle accelerate loading of many jobs:
% module load spindle
% spindle --start-session
% flux submit …
% flux bulksubmit …
% flux run …
% flux submit –wait …
% spindle --end-sessionAll jobs launched inside a spindle session will share a library cache, rather than each job rebuilding and tearing down caches with each run.
Note that when using spindle session mode, spindle config options are set on the spindle –start-session executable command line rather than the flux job launch command line. Use spindle --help to see how these are set.
Tuning Spindle’s Caching Level
There are many options for setting what spindle caches (see the advanced options section). You can pick from some reasonable defaults with the spindle “level” option. On El Capitan “medium” is the default. You can set level to the values “high”, “medium”, “low”, “off”, which are:
- high – Cache executables, libraries, and python file contents. Maintain a negative cache of files that don’t exist. Not that caching executables will break most debuggers.
- medium – Cache libraries and python file contents. Maintain a negative cache of files that don’t exist. This is the default.
- low – Maintain a negative cache of files that don’t exist.
- off – Disable spindle.
Examples of using these would be:
% flux run -o spindle.level=high my_application.exeOr, if using spindle sessions:
% module load spindle
% spindle --start-session --level=high
% flux run my_application.exe
% spindle --end-sessionTuning Spindle’s Python Caching
By default spindle will cache any file opens of *.py, *.pyc, and *.pyo as python libraries. But many python deployments have config and data files that do not have these extensions. Spindle does not cache those config and data files because it does not easily recognize them as read-only python-related files, even though caching them would provide performance improvements. Telling spindle about your python environment or deployment locations can help improve performance by allowing it to cache these config and data files.
The python-prefix option is a colon-separated list of file path string prefixes (or GNU regular expressions). Any file opens that access files under these prefixes will be scalably relocated to local storage and cached. By pointing python-prefix at your python environments and installs, spindle will cache their config and data files.
For example,
% flux run -o spindle.python-prefix=/usr/WS1/legendre/pytorch_env python ddp.py Or if running with spindle sessions:
% spindle --start-session --python-prefix=/usr/WS1/legendre/pytorch_env
% flux run python ddp.py
% spindle --end-sessionBy default, spindle has El Capitan’s and Tuolumne’s system python installs in the python-prefix as:
/collab/usr/gapps/python:/opt/cray/pe/python:/usr/tce/packages/python:[.]*/python[0-9\.]*/site-packages[.]*
Adding your own python prefixes prepends to this list. Putting the NONE keyword as a prefix removes spindle’s default list.
NOTE You can use this option to also have spindle load application data files or configs by pointing it at your data file prefixes—the option is not specific to Python.
Example, Tuning for PyTorch
PyTorch is a critical application to run under Spindle. It creates significant load on the file system and can overwhelm El Capitan’s file system at even dozens of nodes. Using all of the above options can have significant improvements on PyTorch startup. Here is an example of tuning spindle for PyTorch:
% module load spindle
% spindle --start-session --level=high --python-prefix=/usr/WS1/legendre/pytorch_env
% flux submit ... --wait python ddp.py
% spindle --end-sessionThere are several relevant parts to this example:
- We are starting spindle in session mode with the spindle --start-session and spindle --end-session. We used flux’s --wait option to wait until jobs completed before ending the session.
- We are relocating executables with --level=high, which will break traditional debuggers (such as gdb or TotalView). Though since we are running python, we are unlikely to do much traditional debugging.
- We specified --python-prefix=/usr/WS1/legendre/pytorch_env, which is pointed at our pytorch environment. This told spindle to relocate the config and settings files located in the python environment.
Advanced Spindle Options
This section describes advanced options for tuning spindle, which are not needed for most runs.
NUMA Optimization
Spindle’s caching mechanism can change which NUMA domains code and read-only data is allocated to. On most applications this does not significantly matter, though the HPL (High-Performance Linpack) benchmark noticed a 0.5%-1.0% slowdown from spindle’s NUMA allocation changes. Spindle has a --numa option to tune how code pages allocate to numa domains.
Normally, code pages are allocated to a specific NUMA domain based on which process first executes the code page. Depending on synchronization and scheduling, code pages may turn up scattered across different NUMA domains. Each process may or may-not need to reach toward other domains to access any specific memory page. But no process is inherently advantaged over any others.
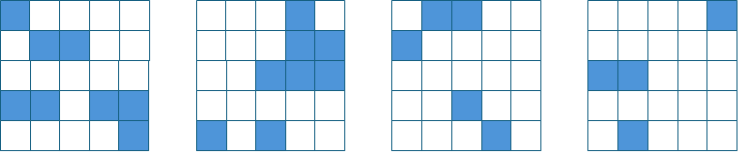
When Spindle is present, the caching mechanism runs as part of a single-process local to one NUMA domain. That spindle process does the first-touch as it puts code pages into its cache, and all pages turn up in one NUMA domain. All processes in the same NUMA domain as Spindle will have faster access to code pages than processes in the other domains, though L1 and L2 caches will typically hide those differences.
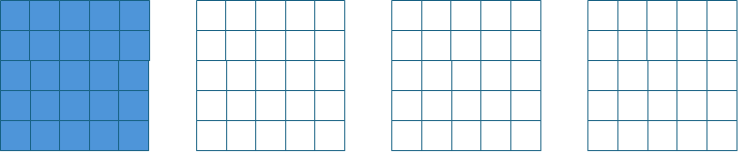
Spindle’s --numa option tells Spindle to make replicate code pages and put a copy into each NUMA domain, trading off memory for performance. Each process will always access each page from its local domain. This could provide faster performance than non-spindle mode, but will quadruple memory usage by code pages.
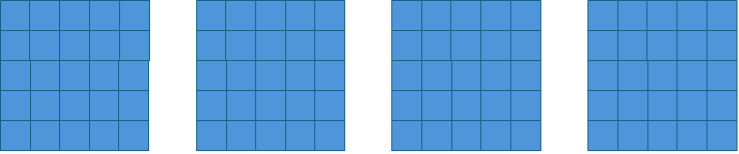
The --numa-excludes and --numa-includes options can be used to tune which files have their code pages replicated. Each option takes a colon-separated list of prefixes. Files under the --numa-excludes prefixes are not replicated. If --numa-includes is specified, then only files under those prefixes have their code pages replicated.
For example:
% spindle --start-session –numa --numa-includes=/g/g0/legendre/myapp/ --numa-excludes=/opt/rocm
% flux run …
% spindle --end-sessionUnder the flux plugin, the numa-includes option is specified as numa-files:
% flux run -o spindle.numa -o spindle.numa-files=/g/g0/legendre/myapp ...SPMD versus MPMD
By default, Spindle is tuned for SPMD (Single-Programs, Multiple-Data) applications. It is expected that a library loaded by one process is loaded by all processes. Thus when any process loads a library, a cached copy of that library is pushed to the cache for every process. Spindle calls this push mode.
Spindle also support MPMD (Multiple-Programs, Multiple-Data) programs, where different programs may run on different nodes. In this mode, Libraries are cached only on nodes that contain a process that loaded that library. This involves more network traffic to coordinate, but may save memory if different nodes have different library footprints. Spindle calls this pull mode.
These options can be specified through the flux command line:
% flux run -o spindle.push ...
-or-
% flux run -o spindle.pull ...Spindle API
Under normal circumstances Spindle runs at the system level and is mostly invisible to applications. Applications can optionally utilize Spindle’s API to performance scalable and cached I/O operations. This API is specified in the spindle.h include file and the libspindle.so library. The spindle include file looks like:
/** * These calls will perform IO operations through Spindle, if present, * and forward on to regular IO calls if Spindle is not present. * The open calls will only forward to Spindle if opening read-only. **/ int spindle_open(const char *pathname, int flags, ...); int spindle_stat(const char *path, struct stat *buf); int spindle_lstat(const char *path, struct stat *buf); FILE *spindle_fopen(const char *path, const char *mode); /** * If spindle is enabled through this API, then all open and stat calls * will automatically be routed through Spindle. * * enable_spindle and disable_spindle are counting calls that must be matched. * Thus if enable_spindle is called twice, disable_spindle must be called twice * to disable Spindle interception. is_spindle_enabled returns the current count. * * Spindle enabling/disabling counts are tracked per-thread (if Spindle was built * with TLS support). **/ void enable_spindle(); void disable_spindle(); int is_spindle_enabled(); /** * is_spindle_present returns true if the application was started under Spindle **/ int is_spindle_present();
The file operations (spindle_open, spindle_stat, spindle_lstat, spindle_fopen) behave like the similarly named GLIBC functions, except they use spindle’s broadcast and cache mechanism to scalably access the file system. It would not be safe to use these to access files that are written during the application’s execution. These operations fall back to the libc behavior if spindle is not running on the application when invoked.
The enable_spindle() and disable_spindle() calls can be used to make spindle operate on every file operation between them. For example, putting enable_spindle() and disable_spindle() around a high-level library call would make every I/O operation in that library go through spindle caching. The is_spindle_enabled() call reports whether this mode is currently enabled.
The is_spindle_present() call tells whether the application was started under spindle.